【题目描述】以软科中国最好大学排名为分析对象,基于requests库和bs4库编写爬虫程序,对2015年至2019年间的中国大学排名数据进行爬取:
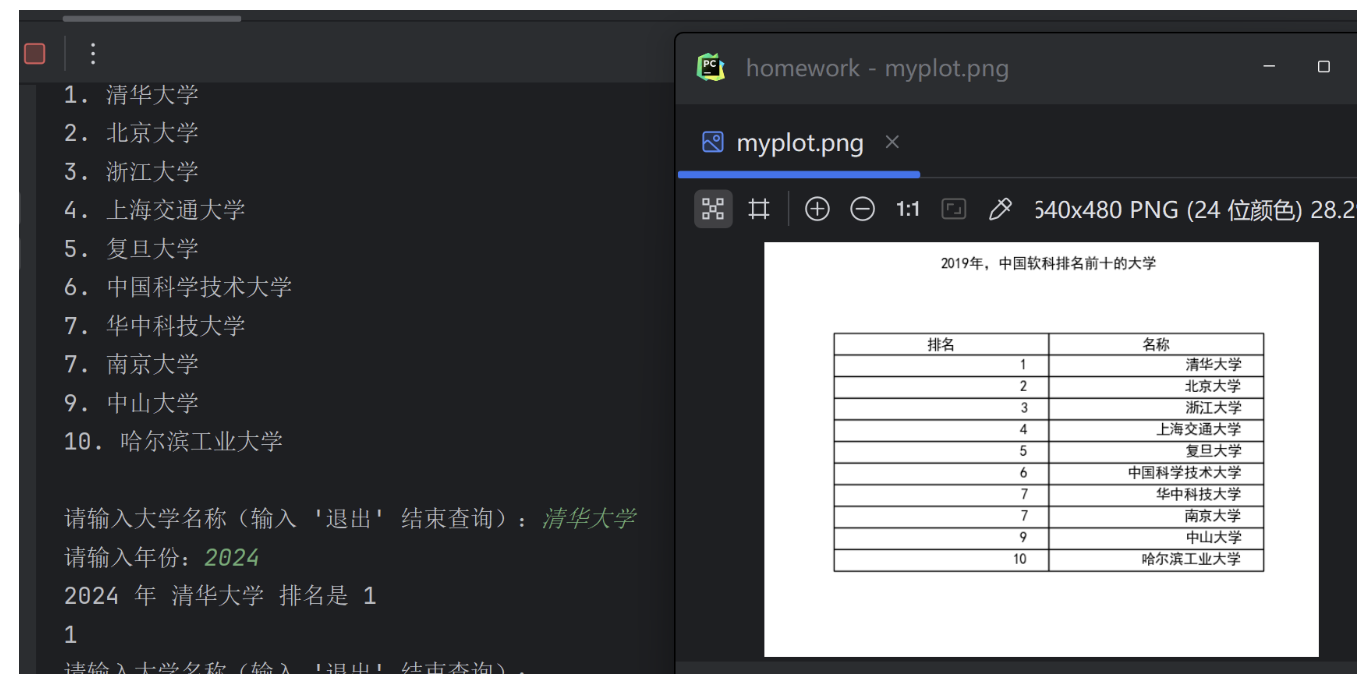
(1)按照排名先后顺序输出不同年份的前10位大学信息,并要求对输出结果的排版进行优化;
(2)结合matplotlib库,对2015-2019年间前10位大学的排名信息进行可视化展示。
(3附加)编写一个查询程序,根据从键盘输入的大学名称和年份,输出该大学相应的排名信息。如果所爬取的数据中不包含该大学或该年份信息,则输出相应的提示信息,并让用户选择重新输入还是结束查询;
【练习要求】请给出源代码程序和运行测试结果,源代码程序要求添加必要的注释。
import requests
from bs4 import BeautifulSoup
import matplotlib.pyplot as plt
from sympy.physics.control.control_plots import matplotlibplt.rcParams['font.sans-serif']=['SimHei'] # 用来设置字体样式以正常显示中文标签
plt.rcParams['axes.unicode_minus']=False # 默认是使用Unicode负号,设置正常显示字符,如正常显示负号# 设置请求头部信息
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3"
}def get_ranking(year):url = f'https://www.shanghairanking.cn/rankings/bcur/{year}.html'# 发送HTTP请求以获取网页内容response = requests.get(url, headers=headers)# 检查请求是否成功if response.status_code == 200:# 使用BeautifulSoup解析HTML内容soup = BeautifulSoup(response.content, 'html.parser')# 找到包含大学信息的表格table = soup.find('table', class_='rk-table')# 提取前10所大学的信息universities = table.find_all('tr', {'data-v-90b0d2ac': True})[1:11] # 排除表头行# 存储排名数据的列表ranking_data = []for university in universities:rank_element = university.find('td', {'data-v-90b0d2ac': True})# 检查排名元素是否存在if rank_element:rank = rank_element.text.strip()name = university.find('a').text.strip()# 将排名数据存储到列表中ranking_data.append({"排名": rank, "名称": name})return ranking_dataelse:print("请求失败。状态码:", response.status_code)def main():# 1. 获取并输出前10位大学信息for year in range(2015, 2020):ranking_data = get_ranking(year)if ranking_data:print(f"{year}年前10所大学:")for data in ranking_data:print(f"{data['排名']}. {data['名称']}")print()# 创建一个表格的figurefig, ax = plt.subplots()# 隐藏坐标轴ax.axis('off')# 创建表格table = ax.table(cellText=[list(data.values()) for data in ranking_data], colLabels=list(ranking_data[0].keys()), loc='center')# 调整表格字体大小table.auto_set_font_size(False)table.set_fontsize(12)# 调整单元格高度table.scale(1, 1.5)# 显示表格plt.title(f"{year}年,中国软科排名前十的大学", pad=20)plt.show()else:print(f"未能获取{year}年的大学排名数据。")def get_specific_ranking(university, year): # Renamed the function# 构建URLurl = f'https://www.shanghairanking.cn/rankings/bcur/{year}.html'# 发送HTTP请求response = requests.get(url)# 检查响应状态码if response.status_code == 200:# 使用BeautifulSoup解析HTML内容soup = BeautifulSoup(response.content, 'html.parser')# 找到包含大学信息的表格table = soup.find('table', class_='rk-table')# 提取前30所大学的信息universities = table.find_all('tr', {'data-v-90b0d2ac': True})[1:31] # 排除表头行# 存储排名数据的列表ranking_data = []for university_row in universities:name_element = university_row.find('a')# 检查大学名称元素是否存在if name_element:name = name_element.text.strip()# 检查大学名称是否与输入的大学名称匹配if name == university:rank_element = university_row.find('td', {'data-v-90b0d2ac': True})if rank_element:rank = rank_element.text.strip()print(f"{year} 年 {university} 排名是 {rank}")return rank# 如果未找到匹配的大学名称,打印消息print(f"找不到 {university} 在 {year} 年的排名信息。")else:print("请求失败。状态码:", response.status_code)if __name__ == "__main__":main()while True:university = input("请输入大学名称(输入 '退出' 结束查询):")if university.lower() == '退出':breakyear = input("请输入年份:")print(get_specific_ranking(university, year))