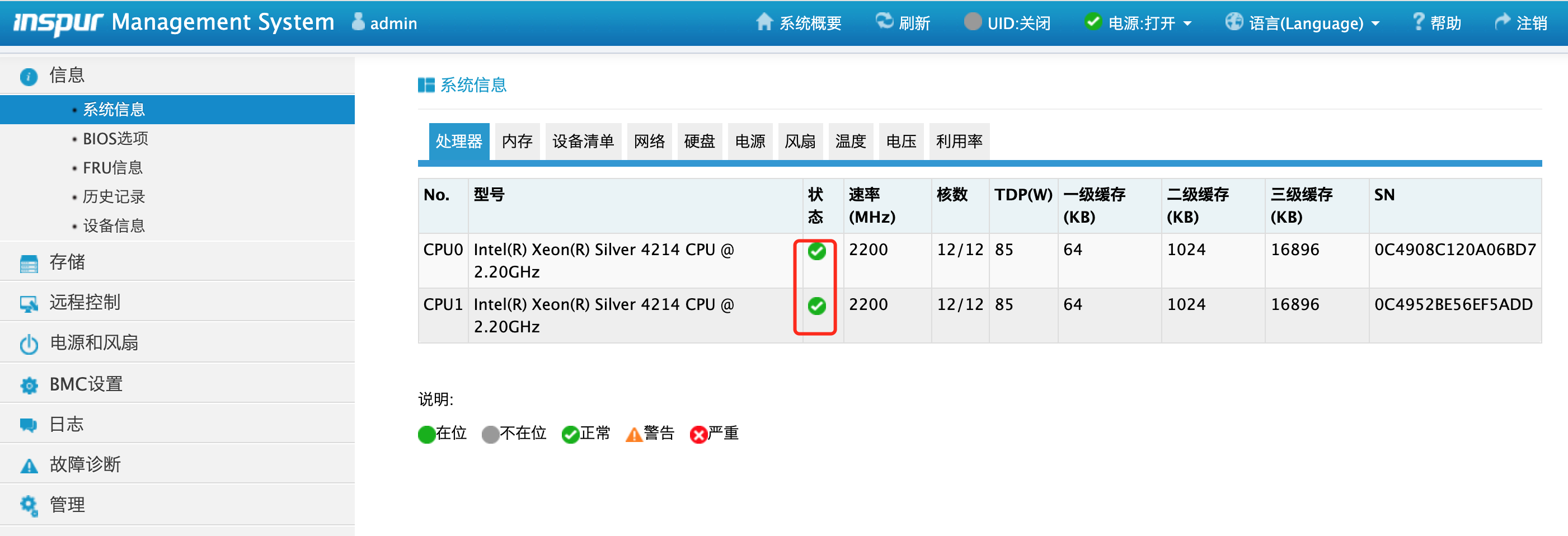
隐马尔科夫模型(Hidden Markov Model, HMM)是一种统计模型,用于描述一个由隐藏的马尔科夫链驱动的随机过程,其中观测序列和状态序列之间存在某种统计依赖关系。HMM通过一组隐藏状态(隐含状态)和观测到的序列来描述系统的行为,通常用于解决时间序列分析、模式识别和自然语言处理中的问题。隐马尔科夫模型最早由Leonard E. Baum及其同事在20世纪60年代提出,用于语音识别领域。随着时间的推移,HMM逐渐发展并应用于各种领域,如生物信息学、金融预测、信号处理等。其核心思想是通过概率论和数理统计方法,在给定观测数据的情况下,推测隐藏状态的最优序列,从而揭示数据的潜在结构。HMM的理论基础包括马尔科夫链、贝叶斯理论和动态规划算法。20世纪80年代,Rabiner等人通过一系列经典论文对HMM进行了系统化和标准化,奠定了其在语音识别和其他应用领域中的基础地位。之后,HMM逐渐与其他机器学习和人工智能技术相结合,形成了丰富的应用场景。
 |
 |
一、隐马尔科夫模型概述
隐马尔可夫模型(Hidden Markov Model,HMM)是用来描述一个含有隐含未知参数的马尔可夫过程,用来描述一个隐含未知量的马尔可夫过程(马尔可夫过程是一类随机过程,它的原始模型是马尔科夫链),它是结构最简单的动态贝叶斯网,是一种著名的有向图模型,主要用于时序数据建模。
1.1隐马尔科夫模型的5个要素和两个假设
隐马尔科夫模型通过五个关键参数来定义,它们共同描述了系统的动态特性。
隐藏状态集合(States):
- \(S = \{s_1, s_2, \ldots, s_N \}\)
- 这些隐藏状态组成了系统的状态空间。每个时间点系统处于某个隐藏状态中,但这些状态是不可观测的(隐含的)。
观测集合(Observations):
- \(V = \{ v_1, v_2, \ldots, v_M \}\)
- 观测集合由可能的观测值组成。每个时间点可以观测到一个观测值,这些值是由系统的隐藏状态生成的。
初始状态分布(Initial State Distribution):
- $ \pi = {\pi_i} \quad \text{where} \quad \pi_i = P(q_1 = s_i) $
- 初始状态分布描述了系统在初始时刻处于各个隐藏状态的概率。
状态转移概率矩阵(State Transition Probability Matrix):
- $A={ a_{ij} } \quad \text{where} \quad a_{ij} = P(q_{t+1} = s_j \mid q_t = s_i) $
- 状态转移概率矩阵描述了系统从一个隐藏状态转移到另一个隐藏状态的概率。
观测概率矩阵(Observation Probability Matrix):
- $ B = {b_{jk}} \quad \text{where} \quad b_{jk} = P(O_t = v_k \mid q_t = s_j)$$
- 观测概率矩阵描述了在某个隐藏状态下生成某个观测值的概率。
隐马尔科夫模型可以表示为
1.2 隐马尔科夫模型的两个假设
隐马尔科夫模型依赖于以下两个基本假设:
有限状态马尔科夫性假设(First-Order Markov Assumption):
- 这个假设表明,系统在某个时间点的状态只依赖于前一个时间点的状态,与更早的状态无关。
- 数学表示为:$ P(q_{t+1} = s_j \mid q_t = s_i, q_{t-1}, \ldots, q_1) = P(q_{t+1} = s_j \mid q_t = s_i) $
- 这个假设简化了状态转移的计算,使得计算量大大降低。
观测独立性假设(Observation Independence Assumption):
- 这个假设表明,给定当前的隐藏状态,观测值与之前或之后的观测值是相互独立的。
- 数学表示为:$ P(O_t = v_k \mid q_t = s_j, O_{t-1}, O_{t-2}, \ldots, O_1) = P(O_t = v_k \mid q_t = s_j)$
- 这一假设使得观测序列的概率计算更为简便,只需考虑当前隐藏状态下的观测概率。
1.3 隐马尔科夫模型优缺点
隐马尔可夫模型(HMM)是一种强大的统计模型,它在处理序列数据方面有着广泛的应用。和所有的模型一样,HMM也有其优点和缺点。
| 优点 | 缺点 |
|---|---|
| 数学理论基础:HMM具有严格的数学推导和算法,这使得它在理论上非常坚实。 | 马尔科夫性假设限制:HMM假设状态转移只依赖于前一个状态,这限制了模型对长距离依赖关系的捕捉能力。 |
| 处理序列数据:HMM特别擅长处理时间序列数据,可以捕捉数据中的动态结构和潜在规律。 | 观察独立性假设:HMM假设观测之间是相互独立的,这在实际应用中往往不成立,限制了模型的表达能力。 |
| 模型简洁:HMM模型结构相对简单,易于理解和实现。 | 参数估计困难:在没有足够数据的情况下,估计HMM的参数可能会非常困难,导致模型性能不佳。 |
| 强大的算法支持:HMM有多种算法支持,如前向-后向算法、维特比算法等,这些算法可以有效地解决评估、解码和学习问题。 | 状态空间限制:HMM通常假设状态空间是有限的且预先定义好的,这在某些情况下可能不适用。 |
| 广泛的应用领域:HMM在语音识别、自然语言处理、生物信息学等多个领域都有应用。 | 对初始状态和状态转移概率敏感:HMM的性能在很大程度上依赖于初始状态概率和状态转移概率的准确性。 |
| 上下文信息利用不足:HMM不能很好地利用上下文信息,因为它只考虑了前一个状态。 |
尽管存在这些缺点,HMM仍然是一个非常有用的工具,特别是在那些可以合理假设观测独立性和状态转移遵循马尔科夫性质的场景中。在实际应用中,研究人员经常通过改进模型或结合其他技术来克服HMM的局限性。
1.4 隐马尔科夫模型的应用
在许多领域得到了广泛应用,以下是一些典型的应用场景:
语音识别:HMM在语音识别中起着重要作用,通过对语音信号进行特征提取,并使用HMM来建模和识别语音信号中的语音模式。
自然语言处理:HMM在分词、词性标注、命名实体识别等任务中被广泛使用,通过隐含状态来建模语言的结构和规律。
生物信息学:HMM用于基因序列分析、蛋白质结构预测和基因功能预测等领域,通过建模生物序列中的模式和变化规律,提供对生物数据的深入理解。
金融预测:HMM在股票价格预测、市场分析和风险管理中有应用,通过分析金融时间序列数据中的隐含状态和转移规律,帮助投资者做出决策。
图像处理和计算机视觉:HMM在手写识别、目标跟踪和图像分割等任务中有应用,通过建模图像中的时间或空间变化,进行模式识别和分析。
模式识别:HMM可以用于识别图像、视频中的模式,例如手势识别或行为识别。
医疗健康:在医疗领域,HMM被用于疾病的发展阶段建模、心电图分析等。
网络流量分析:HMM可以用于分析网络流量,检测异常行为或入侵检测。
信号处理:在各种信号处理任务中,HMM用于分析和解释信号数据,如雷达信号或地震信号分析。
二、隐马尔科夫模型基础
一个隐马尔科夫模型可以表示为一个三元组:\(\lambda = (\pi, A, B)\),其中:\(\pi\)是初始状态分布向量;\(A\)是状态转移概率矩阵;\(B\) 是观测概率矩阵。
2.1 HMM的三个基本问题
隐马尔科夫模型(Hidden Markov Model, HMM)涉及三个基本问题:评估问题(Evaluation Problem)、解码问题(Decoding Problem)和学习问题(Learning Problem)。每个问题都有其特定的数学表达方式。
- 评估问题(Evaluation Problem)
问题描述:给定模型参数 \(\lambda = (\pi, A, B)\) 和观测序列\(O = (O_1, O_2, \ldots, O_T)\),计算观测序列的概率 \(P(O \mid \lambda)\)。
数学表达:
其中,\(Q = (q_1, q_2, \ldots, q_T)\) 是所有可能的隐藏状态序列。
使用前向算法(Forward Algorithm)进行高效计算,用于计算观测序列 \(O =\{O_1, O_2, \ldots, O_T\}\)的概率\(P(O \mid \lambda)\)。
初始化:
$$ \alpha_1(i) = \pi_i b_i(O_1) \quad \text{for} \quad 1 \leq i \leq N $$
递归:
- 解码问题(Decoding Problem)
问题描述:给定模型参数 \(\lambda = (\pi, A, B)\) 和观测序列 \(O = (O_1, O_2, \ldots, O_T)\),找到最可能的隐藏状态序列 \(Q = (q_1, q_2, \ldots, q_T)\)。
数学表达:
使用维特比算法(Viterbi Algorithm)进行高效计算,用于找到给定观测序列的最可能隐藏状态序列。
初始化:
**递归**:
**终止**:
**路径回溯**:
- 学习问题(Learning Problem)
问题描述:给定观测序列 $ O = (O_1, O_2, \ldots, O_T) $,估计模型参数 $\lambda = (\pi, A, B) $ 使得 $ P(O \mid \lambda) $ 最大。
使用Baum-Welch算法(也称为EM算法)进行参数估计。
Baum-Welch算法(Baum-Welch Algorithm),用于估计模型参数 \(\lambda = (\pi, A, B)\)。
计算前向概率 $\alpha $ 和后向概率\(\beta\):
前向概率:\[\alpha_t(i) = P(O_1, O_2, \ldots, O_t, q_t = s_i \mid \lambda) \]后向概率:\[\beta_t(i) = P(O_{t+1}, O_{t+2}, \ldots, O_T \mid q_t = s_i, \lambda) \]期望步骤:\[ \xi_t(i, j) = \frac{\alpha_t(i) a_{ij} b_j(O_{t+1}) \beta_{t+1}(j)}{\sum_{i=1}^{N} \sum_{j=1}^{N} \alpha_t(i) a_{ij} b_j(O_{t+1}) \beta_{t+1}(j)} \\ \gamma_t(i) = \sum_{j=1}^{N} \xi_t(i, j)\]最大化步骤:\[\pi_i = \gamma_1(i)\\a_{ij} = \frac{\sum_{t=1}^{T-1} \xi_t(i, j)}{\sum_{t=1}^{T-1} \gamma_t(i)} \\ b_j(k) = \frac{\sum_{t=1, O_t = v_k}^{T} \gamma_t(j)}{\sum_{t=1}^{T} \gamma_t(j)}\]
2.2 隐马尔科夫模型实例
隐马尔可夫模型(HMM)在乡村诊所病人感冒预测。想象一个乡村诊所,村民的身体状况要么是健康(Healthy),要么是发烧(Fever)。只有通过询问医生,才能知道是否发烧。医生通过询问村民的感觉去诊断他们是否发烧。村民的感觉有以下几种:正常(normal)、冷(cold)或头晕(dizzy)。
假设一个病人每天来到诊所并告诉医生他的感觉,病人的健康状况是一个离散马尔可夫链。病人的状态有两种:健康和发烧,但医生不能直接观察到,这意味着状态对医生是不可见的。每天病人会告诉医生自己有以下几种由他的健康状态决定的感觉的一种:正常、冷或头晕。这些是观察结果。 整个系统为一个隐马尔可夫模型(HMM)。
现状:医生知道村民的总体健康状况,还知道发烧和没发烧的病人通常会表明自己有什么症状。 换句话说,医生知道隐马尔可夫模型的参数。
根据收集到的信息,得出以下的数据。
病人的状态,也就是Q(‘Healthy’, ‘Fever’)
病人的感觉,即观测状态,也就是V:(‘normal’, ‘cold’, ‘dizzy’)
π是初始状态概率向量:{‘Healthy’: 0.6, ‘Fever’: 0.4}
- 隐马尔可夫模型参数
状态集合: Q = {'Healthy', 'Fever'}
观测集合: V = {'normal', 'cold', 'dizzy'}
初始状态概率向量 π:
{'Healthy': 0.6,'Fever': 0.4}
状态转移概率矩阵 transition_probability:
{'Healthy': {'Healthy': 0.7, 'Fever': 0.3},'Fever': {'Healthy': 0.4, 'Fever': 0.6},
}
观测概率矩阵 emission_probability:
{'Healthy': {'normal': 0.5, 'cold': 0.4, 'dizzy': 0.1},'Fever': {'normal': 0.1, 'cold': 0.3, 'dizzy': 0.6},
}
评估问题:已知模型 $λ = (A, B, π) $和观测序列 \(O = o1, o2, …, oT\),计算在模型 \(λ\)下某种观测序列\(O\)出现的概率\(P(O|λ)\)。也就是HMM模型参数\(A, B,π\)已知。求病人出现一系列症状的概率?
学习问题:已知观测序列 \(O = o1, o2, …, oT\),估计模型参数\(λ = (A, B, π)\),使 \(P(O|λ)\) 最大。也就是通过病人表现的一系列的症状,估计出现这一系列症状的最佳模型参数。采用极大似然法的方法估计参数,通常使用EM算法。
预测问题(解码问题):已知观测序列 \(O = o1, o2, …, oT\) 和模型参数 \(λ = (A, B, π)\),求给定观测序列条件概率$ P(I|O)$ 最大的状态序列 \(I = (i1, i2, …, iT)\)。也就是通过观测 \(V\) 的状态链,去预测这几天病人是否有感冒等状态。
2.3 Python实现
import numpy as np# 初始化参数
states = ['Rainy', 'Sunny']
observations = ['Walk', 'Shop', 'Clean']
start_prob = np.array([0.6, 0.4])
trans_prob = np.array([[0.7, 0.3],[0.4, 0.6]])
emission_prob = np.array([[0.1, 0.4, 0.5],[0.6, 0.3, 0.1]])# 将观测序列转换为索引
obs_seq = [0, 1, 2] # 'Walk', 'Shop', 'Clean'# 前向算法
def forward(obs_seq, start_prob, trans_prob, emission_prob):N = len(states)T = len(obs_seq)alpha = np.zeros((T, N))alpha[0, :] = start_prob * emission_prob[:, obs_seq[0]]for t in range(1, T):for j in range(N):alpha[t, j] = np.sum(alpha[t-1, :] * trans_prob[:, j]) * emission_prob[j, obs_seq[t]]return np.sum(alpha[-1, :])# 维特比算法
def viterbi(obs_seq, start_prob, trans_prob, emission_prob):N = len(states)T = len(obs_seq)delta = np.zeros((T, N))psi = np.zeros((T, N), dtype=int)delta[0, :] = start_prob * emission_prob[:, obs_seq[0]]for t in range(1, T):for j in range(N):delta[t, j] = np.max(delta[t-1, :] * trans_prob[:, j]) * emission_prob[j, obs_seq[t]]psi[t, j] = np.argmax(delta[t-1, :] * trans_prob[:, j])path = np.zeros(T, dtype=int)path[-1] = np.argmax(delta[-1, :])for t in range(T-2, -1, -1):path[t] = psi[t+1, path[t+1]]return path# Baum-Welch算法
def baum_welch(obs_seq, N, M, max_iter=100):T = len(obs_seq)a = np.random.rand(N, N)a = a / a.sum(axis=1, keepdims=True)b = np.random.rand(N, M)b = b / b.sum(axis=1, keepdims=True)pi = np.random.rand(N)pi = pi / pi.sum()for _ in range(max_iter):alpha = np.zeros((T, N))alpha[0, :] = pi * b[:, obs_seq[0]]for t in range(1, T):for j in range(N):alpha[t, j] = np.sum(alpha[t-1, :] * a[:, j]) * b[j, obs_seq[t]]beta = np.zeros((T, N))beta[-1, :] = 1for t in range(T-2, -1, -1):for i in range(N):beta[t, i] = np.sum(beta[t+1, :] * a[i, :] * b[:, obs_seq[t+1]])xi = np.zeros((T-1, N, N))for t in range(T-1):denom = np.sum(alpha[t, :] * np.sum(a * b[:, obs_seq[t+1]].T * beta[t+1, :], axis=1))for i in range(N):numer = alpha[t, i] * a[i, :] * b[:, obs_seq[t+1]].T * beta[t+1, :]xi[t, i, :] = numer / denomgamma = np.sum(xi, axis=2)pi = gamma[0, :]for i in range(N):for j in range(N):a[i, j] = np.sum(xi[:, i, j]) / np.sum(gamma[:, i])gamma = np.hstack((gamma, np.sum(xi[-1, :, :], axis=1, keepdims=True)))for j in range(M):mask = np.array(obs_seq) == jb[:, j] = np.sum(gamma[:, mask], axis=1) / np.sum(gamma, axis=1)return a, b, pi# 计算评估问题
prob = forward(obs_seq, start_prob, trans_prob, emission_prob)
print(f"观测序列的概率: {prob}")# 计算解码问题
path = viterbi(obs_seq, start_prob, trans_prob, emission_prob)
hidden_states = [states[i] for i in path]
print(f"最可能的隐藏状态序列: {hidden_states}")# 计算学习问题
a, b, pi = baum_welch(obs_seq, len(states), len(observations))
print(f"重新估计的状态转移矩阵: \n{a}")
print(f"重新估计的观测概率矩阵: \n{b}")
print(f"重新估计的初始状态分布: \n{pi}")
观测序列的概率: 0.033612
最可能的隐藏状态序列: ['Sunny', 'Rainy', 'Rainy']
重新估计的状态转移矩阵:
[[0. 1.][0. 1.]]
重新估计的观测概率矩阵:
[[1. 0. 0. ][0. 0.5 0.5]]
重新估计的初始状态分布:
[1. 0.]
三、Python应用
3.1 手写识别
给定一个手写字符的数据集,任务是根据字符的形状识别字符。在这个例子中,状态空间被定义为状态,这是一个26个可能字符的列表。观察空间被定义为观察,其是8个可能的观察的列表,表示手写体中的笔划的方向。初始状态分布定义为start_probability,它是一个概率数组,表示第一个状态是26个字符中任何一个的概率。状态转换概率定义为transition_probability,它是一个26×26的数组,表示从一个字符转换到另一个字符的概率。观测似然度被定义为emission_probability,它是一个26×8的数组,表示从每个字符生成每个观测的概率。
HMM模型是使用hmmlearn库中的hmm.MultinomialHMM类定义的,模型的参数是使用模型对象的startprob_、transmat_和emissionprob_属性设置的。
观察序列定义为observations_sequence,是一个长度为11的数组,表示手写体中的11个笔画。模型对象的predict方法用于在给定观测值的情况下预测最可能的隐藏状态。结果存储在hidden_states变量中,该变量是一个长度为11的数组,表示每个笔划最可能的字符。
# import the necessary libraries
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from hmmlearn import hmm # Define the state space
states = ["A", "B", "C", "D", "E", "F", "G", "H", "I", "J", "K", "L", "M", "N", "O", "P", "Q", "R", "S", "T", "U", "V", "W", "X", "Y", "Z"]
n_states = len(states) # Define the observation space
observations = ["up", "down", "left", "right", "up-right", "down-right", "down-left", "up-left"]
n_observations = len(observations) # Define the initial state distribution
start_probability = np.random.dirichlet(np.ones(26),size=(1))[0] # Define the state transition probabilities
transition_probability = np.random.dirichlet(np.ones(26),size=(26)) # Define the observation likelihoods
emission_probability = np.random.dirichlet(np.ones(26),size=(26)) # Fit the model
model = hmm.CategoricalHMM(n_components=n_states)
model.startprob_ = start_probability
model.transmat_ = transition_probability
model.emissionprob_ = emission_probability # Define the sequence of observations
observations_sequence = np.array([0, 1, 2, 1, 0, 1, 2, 3, 2, 1, 2]).reshape(-1, 1) # Predict the most likely hidden states
hidden_states = model.predict(observations_sequence)
print("Most likely hidden states:", hidden_states) # Plot the results
sns.set_style("whitegrid")
plt.plot(hidden_states, '-o', label="Hidden State")
plt.xlabel('Stroke')
plt.ylabel('Most Likely Hidden State')
plt.title("Predicted hidden state")
plt.legend()
plt.show()

3.2 语音识别
给定音频记录的数据集,任务是识别录音中所说的单词。在该示例中,状态空间被定义为状态,其是表示静音或3个不同单词之一的存在的4个可能状态的列表。观测空间被定义为观测,其是表示语音音量的2个可能观测的列表。初始状态分布被定义为start_probability,它是长度为4的概率数组,表示每个状态是初始状态的概率。
状态转移概率被定义为transition_probability,它是一个4×4矩阵,表示从一个状态转移到另一个状态的概率。观测似然被定义为emission_probability,它是一个4×2矩阵,表示每个状态发出观测的概率。该模型使用hmmlearn库中的MultinomialHMM类定义,并使用startprob_、transmat_和emissionprob_属性拟合。观测序列定义为observations_sequence,是一个长度为8的数组,表示8个不同时间步长中的语音音量。模型对象的predict方法用于在给定观测值的情况下预测最可能的隐藏状态。结果存储在hidden_states变量中,该变量是一个长度为8的数组,表示每个时间步最可能的状态。
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from hmmlearn import hmm # Define the state space
states = ["Silence", "Word1", "Word2", "Word3"]
n_states = len(states) # Define the observation space
observations = ["Loud", "Soft"]
n_observations = len(observations) # Define the initial state distribution
start_probability = np.array([0.8, 0.1, 0.1, 0.0]) # Define the state transition probabilities
transition_probability = np.array([[0.7, 0.2, 0.1, 0.0], [0.0, 0.6, 0.4, 0.0], [0.0, 0.0, 0.6, 0.4], [0.0, 0.0, 0.0, 1.0]]) # Define the observation likelihoods
emission_probability = np.array([[0.7, 0.3], [0.4, 0.6], [0.6, 0.4], [0.3, 0.7]]) # Fit the model
model = hmm.CategoricalHMM(n_components=n_states)
model.startprob_ = start_probability
model.transmat_ = transition_probability
model.emissionprob_ = emission_probability # Define the sequence of observations
observations_sequence = np.array([0, 1, 0, 0, 1, 1, 0, 1]).reshape(-1, 1) # Predict the most likely hidden states
hidden_states = model.predict(observations_sequence)
print("Most likely hidden states:", hidden_states) # Plot the results
sns.set_style("darkgrid")
plt.plot(hidden_states, '-o', label="Hidden State")
plt.legend()
plt.show()
#Most likely hidden states: [0 1 2 2 3 3 3 3]

总结
隐马尔科夫模型作为一种强大的统计工具,通过建模隐藏状态和观测数据之间的依赖关系,在许多领域中得到了广泛应用。其核心理论和算法,包括前向后向算法、维特比算法和Baum-Welch算法,为解决复杂的时间序列分析和模式识别问题提供了有效的方法。随着计算能力的提高和数据量的增加,HMM在机器学习和人工智能中的应用前景更加广阔。
尽管HMM具有强大的建模能力,但其假设条件(如状态之间的独立性和观测的马尔科夫性)在某些情况下可能受到限制。为了克服这些限制,研究者们提出了许多改进和扩展方法,如条件随机场(CRF)、动态贝叶斯网络(DBN)等,以适应更复杂的实际问题。然而,隐马尔科夫模型作为一种经典方法,其理论基础和实际应用仍然是理解和解决许多统计建模问题的关键。