这里有一篇很好的博客宋宝华:论Linux的页迁移(Page Migration)完整版-CSDN博客
为什么需要页面迁移?试想系统在经过长时间运行,内存块趋于碎片化,想要分配一块大的连续内存已经不可能了。此时并非没有足够的内存,而只是内存碎片化。这个时候如果可以是已经分配的内存聚集在一起就可以得到大块的连续内存,这就是内存规整,依赖的技术就是内存迁移。除了内存规整,node balance,virtio-balloon等都会引发内存迁移。甚至于常见的写时复制也可以看作时内存迁移。
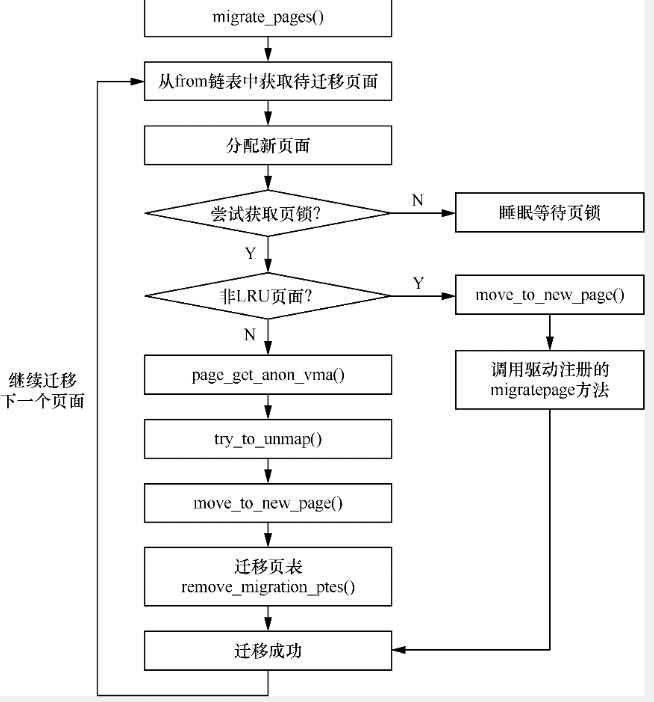
内存迁移具体含义就是首先找到一块目标页,把当前页的内容copy到目标页,断开当前页的映射,重新建立到目标页的映射。这是一个比较复杂的过程。
内核负责页面迁移的函数是migrate_pages
/** migrate_pages - migrate the folios specified in a list, to the free folios* supplied as the target for the page migration** @from: The list of folios to be migrated.* @get_new_folio: The function used to allocate free folios to be used* as the target of the folio migration.* @put_new_folio: The function used to free target folios if migration* fails, or NULL if no special handling is necessary.* @private: Private data to be passed on to get_new_folio()* @mode: The migration mode that specifies the constraints for* folio migration, if any.* @reason: The reason for folio migration.* @ret_succeeded: Set to the number of folios migrated successfully if* the caller passes a non-NULL pointer.** The function returns after NR_MAX_MIGRATE_PAGES_RETRY attempts or if no folios* are movable any more because the list has become empty or no retryable folios* exist any more. It is caller's responsibility to call putback_movable_pages()* only if ret != 0.** Returns the number of {normal folio, large folio, hugetlb} that were not* migrated, or an error code. The number of large folio splits will be* considered as the number of non-migrated large folio, no matter how many* split folios of the large folio are migrated successfully.*/ int migrate_pages(struct list_head *from, new_folio_t get_new_folio,free_folio_t put_new_folio, unsigned long private,enum migrate_mode mode, int reason, unsigned int *ret_succeeded) {int rc, rc_gather;int nr_pages;struct folio *folio, *folio2;LIST_HEAD(folios);LIST_HEAD(ret_folios);LIST_HEAD(split_folios);struct migrate_pages_stats stats;trace_mm_migrate_pages_start(mode, reason);memset(&stats, 0, sizeof(stats));rc_gather = migrate_hugetlbs(from, get_new_folio, put_new_folio, private,mode, reason, &stats, &ret_folios);if (rc_gather < 0)goto out;again:nr_pages = 0;list_for_each_entry_safe(folio, folio2, from, lru) {/* Retried hugetlb folios will be kept in list */if (folio_test_hugetlb(folio)) {list_move_tail(&folio->lru, &ret_folios);continue;}nr_pages += folio_nr_pages(folio);if (nr_pages >= NR_MAX_BATCHED_MIGRATION)break;}if (nr_pages >= NR_MAX_BATCHED_MIGRATION)list_cut_before(&folios, from, &folio2->lru);elselist_splice_init(from, &folios);if (mode == MIGRATE_ASYNC)
//异步页面迁移rc = migrate_pages_batch(&folios, get_new_folio, put_new_folio,private, mode, reason, &ret_folios,&split_folios, &stats,NR_MAX_MIGRATE_PAGES_RETRY);else
//同步页面迁移rc = migrate_pages_sync(&folios, get_new_folio, put_new_folio,private, mode, reason, &ret_folios,&split_folios, &stats);list_splice_tail_init(&folios, &ret_folios);if (rc < 0) {rc_gather = rc;list_splice_tail(&split_folios, &ret_folios);goto out;}if (!list_empty(&split_folios)) {/** Failure isn't counted since all split folios of a large folio* is counted as 1 failure already. And, we only try to migrate* with minimal effort, force MIGRATE_ASYNC mode and retry once.*/migrate_pages_batch(&split_folios, get_new_folio,put_new_folio, private, MIGRATE_ASYNC, reason,&ret_folios, NULL, &stats, 1);list_splice_tail_init(&split_folios, &ret_folios);}rc_gather += rc;if (!list_empty(from))goto again; out:/** Put the permanent failure folio back to migration list, they* will be put back to the right list by the caller.*/list_splice(&ret_folios, from);/** Return 0 in case all split folios of fail-to-migrate large folios* are migrated successfully.*/if (list_empty(from))rc_gather = 0;count_vm_events(PGMIGRATE_SUCCESS, stats.nr_succeeded);count_vm_events(PGMIGRATE_FAIL, stats.nr_failed_pages);count_vm_events(THP_MIGRATION_SUCCESS, stats.nr_thp_succeeded);count_vm_events(THP_MIGRATION_FAIL, stats.nr_thp_failed);count_vm_events(THP_MIGRATION_SPLIT, stats.nr_thp_split);trace_mm_migrate_pages(stats.nr_succeeded, stats.nr_failed_pages,stats.nr_thp_succeeded, stats.nr_thp_failed,stats.nr_thp_split, stats.nr_split, mode,reason);if (ret_succeeded)*ret_succeeded = stats.nr_succeeded;return rc_gather; }
入参中的函数指针
typedef struct folio *new_folio_t(struct folio *folio, unsigned long private); typedef void free_folio_t(struct folio *folio, unsigned long private);
get_new_folio用来分配页面。put_new_folio用来释放新分配的页面如果迁移失败。
异步回收函数
/** migrate_pages_batch() first unmaps folios in the from list as many as* possible, then move the unmapped folios.** We only batch migration if mode == MIGRATE_ASYNC to avoid to wait a* lock or bit when we have locked more than one folio. Which may cause* deadlock (e.g., for loop device). So, if mode != MIGRATE_ASYNC, the* length of the from list must be <= 1.*/ static int migrate_pages_batch(struct list_head *from,new_folio_t get_new_folio, free_folio_t put_new_folio,unsigned long private, enum migrate_mode mode, int reason,struct list_head *ret_folios, struct list_head *split_folios,struct migrate_pages_stats *stats, int nr_pass) {int retry = 1;int thp_retry = 1;int nr_failed = 0;int nr_retry_pages = 0;int pass = 0;bool is_thp = false;bool is_large = false;struct folio *folio, *folio2, *dst = NULL, *dst2;int rc, rc_saved = 0, nr_pages;LIST_HEAD(unmap_folios);LIST_HEAD(dst_folios);bool nosplit = (reason == MR_NUMA_MISPLACED);VM_WARN_ON_ONCE(mode != MIGRATE_ASYNC &&!list_empty(from) && !list_is_singular(from));for (pass = 0; pass < nr_pass && retry; pass++) {retry = 0;thp_retry = 0;nr_retry_pages = 0;list_for_each_entry_safe(folio, folio2, from, lru) {is_large = folio_test_large(folio);is_thp = is_large && folio_test_pmd_mappable(folio);nr_pages = folio_nr_pages(folio);cond_resched();/** Large folio migration might be unsupported or* the allocation might be failed so we should retry* on the same folio with the large folio split* to normal folios.** Split folios are put in split_folios, and* we will migrate them after the rest of the* list is processed.*/if (!thp_migration_supported() && is_thp) {nr_failed++;stats->nr_thp_failed++;if (!try_split_folio(folio, split_folios)) {stats->nr_thp_split++;stats->nr_split++;continue;}stats->nr_failed_pages += nr_pages;list_move_tail(&folio->lru, ret_folios);continue;}//解除folio的虚拟映射rc = migrate_folio_unmap(get_new_folio, put_new_folio,private, folio, &dst, mode, reason,ret_folios);/** The rules are:* Success: folio will be freed* Unmap: folio will be put on unmap_folios list,* dst folio put on dst_folios list* -EAGAIN: stay on the from list* -ENOMEM: stay on the from list* Other errno: put on ret_folios list*/switch(rc) {case -ENOMEM:/** When memory is low, don't bother to try to migrate* other folios, move unmapped folios, then exit.*/nr_failed++;stats->nr_thp_failed += is_thp;/* Large folio NUMA faulting doesn't split to retry. */if (is_large && !nosplit) {int ret = try_split_folio(folio, split_folios);if (!ret) {stats->nr_thp_split += is_thp;stats->nr_split++;break;} else if (reason == MR_LONGTERM_PIN &&ret == -EAGAIN) {/** Try again to split large folio to* mitigate the failure of longterm pinning.*/retry++;thp_retry += is_thp;nr_retry_pages += nr_pages;/* Undo duplicated failure counting. */nr_failed--;stats->nr_thp_failed -= is_thp;break;}}stats->nr_failed_pages += nr_pages + nr_retry_pages;/* nr_failed isn't updated for not used */stats->nr_thp_failed += thp_retry;rc_saved = rc;if (list_empty(&unmap_folios))goto out;elsegoto move;case -EAGAIN:retry++;thp_retry += is_thp;nr_retry_pages += nr_pages;break;case MIGRATEPAGE_SUCCESS:stats->nr_succeeded += nr_pages;stats->nr_thp_succeeded += is_thp;break;case MIGRATEPAGE_UNMAP:list_move_tail(&folio->lru, &unmap_folios);list_add_tail(&dst->lru, &dst_folios);break;default:/** Permanent failure (-EBUSY, etc.):* unlike -EAGAIN case, the failed folio is* removed from migration folio list and not* retried in the next outer loop.*/nr_failed++;stats->nr_thp_failed += is_thp;stats->nr_failed_pages += nr_pages;break;}}}nr_failed += retry;stats->nr_thp_failed += thp_retry;stats->nr_failed_pages += nr_retry_pages; move:/* Flush TLBs for all unmapped folios */try_to_unmap_flush();retry = 1;for (pass = 0; pass < nr_pass && retry; pass++) {retry = 0;thp_retry = 0;nr_retry_pages = 0;dst = list_first_entry(&dst_folios, struct folio, lru);dst2 = list_next_entry(dst, lru);list_for_each_entry_safe(folio, folio2, &unmap_folios, lru) {is_thp = folio_test_large(folio) && folio_test_pmd_mappable(folio);nr_pages = folio_nr_pages(folio);cond_resched();//将旧页内容迁移到新页rc = migrate_folio_move(put_new_folio, private,folio, dst, mode,reason, ret_folios);/** The rules are:* Success: folio will be freed* -EAGAIN: stay on the unmap_folios list* Other errno: put on ret_folios list*/switch(rc) {case -EAGAIN:retry++;thp_retry += is_thp;nr_retry_pages += nr_pages;break;case MIGRATEPAGE_SUCCESS:stats->nr_succeeded += nr_pages;stats->nr_thp_succeeded += is_thp;break;default:nr_failed++;stats->nr_thp_failed += is_thp;stats->nr_failed_pages += nr_pages;break;}dst = dst2;dst2 = list_next_entry(dst, lru);}}nr_failed += retry;stats->nr_thp_failed += thp_retry;stats->nr_failed_pages += nr_retry_pages;rc = rc_saved ? : nr_failed; out:/* Cleanup remaining folios */dst = list_first_entry(&dst_folios, struct folio, lru);dst2 = list_next_entry(dst, lru);list_for_each_entry_safe(folio, folio2, &unmap_folios, lru) {int old_page_state = 0;struct anon_vma *anon_vma = NULL;__migrate_folio_extract(dst, &old_page_state, &anon_vma);migrate_folio_undo_src(folio, old_page_state & PAGE_WAS_MAPPED,anon_vma, true, ret_folios);list_del(&dst->lru);migrate_folio_undo_dst(dst, true, put_new_folio, private);dst = dst2;dst2 = list_next_entry(dst, lru);}return rc; }
从from list中循环取得folio,解除映射然后将旧页的内容move到新页。这里是批量操作,只有在异步情况下才能这么做。
/* Obtain the lock on page, remove all ptes. */ static int migrate_folio_unmap(new_folio_t get_new_folio,free_folio_t put_new_folio, unsigned long private,struct folio *src, struct folio **dstp, enum migrate_mode mode,enum migrate_reason reason, struct list_head *ret) {struct folio *dst;int rc = -EAGAIN;int old_page_state = 0;struct anon_vma *anon_vma = NULL;bool is_lru = !__folio_test_movable(src);bool locked = false;bool dst_locked = false;if (folio_ref_count(src) == 1) {
//这里为啥引用为1就说明folio可以释放了?/* Folio was freed from under us. So we are done. */folio_clear_active(src);folio_clear_unevictable(src);/* free_pages_prepare() will clear PG_isolated. */list_del(&src->lru);migrate_folio_done(src, reason);return MIGRATEPAGE_SUCCESS;}//使用函数指针分配页面dst = get_new_folio(src, private);if (!dst)return -ENOMEM;*dstp = dst;dst->private = NULL;if (!folio_trylock(src)) {if (mode == MIGRATE_ASYNC)goto out;/** It's not safe for direct compaction to call lock_page.* For example, during page readahead pages are added locked* to the LRU. Later, when the IO completes the pages are* marked uptodate and unlocked. However, the queueing* could be merging multiple pages for one bio (e.g.* mpage_readahead). If an allocation happens for the* second or third page, the process can end up locking* the same page twice and deadlocking. Rather than* trying to be clever about what pages can be locked,* avoid the use of lock_page for direct compaction* altogether.*/if (current->flags & PF_MEMALLOC)goto out;/** In "light" mode, we can wait for transient locks (eg* inserting a page into the page table), but it's not* worth waiting for I/O.*/if (mode == MIGRATE_SYNC_LIGHT && !folio_test_uptodate(src))goto out;folio_lock(src);}locked = true;if (folio_test_mlocked(src))old_page_state |= PAGE_WAS_MLOCKED;if (folio_test_writeback(src)) {/** Only in the case of a full synchronous migration is it* necessary to wait for PageWriteback. In the async case,* the retry loop is too short and in the sync-light case,* the overhead of stalling is too much*/switch (mode) {case MIGRATE_SYNC:case MIGRATE_SYNC_NO_COPY:break;default:rc = -EBUSY;goto out;}
//等待回写folio_wait_writeback(src);}/** By try_to_migrate(), src->mapcount goes down to 0 here. In this case,* we cannot notice that anon_vma is freed while we migrate a page.* This get_anon_vma() delays freeing anon_vma pointer until the end* of migration. File cache pages are no problem because of page_lock()* File Caches may use write_page() or lock_page() in migration, then,* just care Anon page here.** Only folio_get_anon_vma() understands the subtleties of* getting a hold on an anon_vma from outside one of its mms.* But if we cannot get anon_vma, then we won't need it anyway,* because that implies that the anon page is no longer mapped* (and cannot be remapped so long as we hold the page lock).*/if (folio_test_anon(src) && !folio_test_ksm(src))anon_vma = folio_get_anon_vma(src);/** Block others from accessing the new page when we get around to* establishing additional references. We are usually the only one* holding a reference to dst at this point. We used to have a BUG* here if folio_trylock(dst) fails, but would like to allow for* cases where there might be a race with the previous use of dst.* This is much like races on refcount of oldpage: just don't BUG().*/if (unlikely(!folio_trylock(dst)))goto out;dst_locked = true;if (unlikely(!is_lru)) {__migrate_folio_record(dst, old_page_state, anon_vma);return MIGRATEPAGE_UNMAP;}/** Corner case handling:* 1. When a new swap-cache page is read into, it is added to the LRU* and treated as swapcache but it has no rmap yet.* Calling try_to_unmap() against a src->mapping==NULL page will* trigger a BUG. So handle it here.* 2. An orphaned page (see truncate_cleanup_page) might have* fs-private metadata. The page can be picked up due to memory* offlining. Everywhere else except page reclaim, the page is* invisible to the vm, so the page can not be migrated. So try to* free the metadata, so the page can be freed.*/if (!src->mapping) {if (folio_test_private(src)) {try_to_free_buffers(src);goto out;}} else if (folio_mapped(src)) {/* Establish migration ptes */VM_BUG_ON_FOLIO(folio_test_anon(src) &&!folio_test_ksm(src) && !anon_vma, src);
//替换pte为swap entrytry_to_migrate(src, mode == MIGRATE_ASYNC ? TTU_BATCH_FLUSH : 0);old_page_state |= PAGE_WAS_MAPPED;}if (!folio_mapped(src)) {__migrate_folio_record(dst, old_page_state, anon_vma);return MIGRATEPAGE_UNMAP;}out:/** A folio that has not been unmapped will be restored to* right list unless we want to retry.*/if (rc == -EAGAIN)ret = NULL;migrate_folio_undo_src(src, old_page_state & PAGE_WAS_MAPPED,anon_vma, locked, ret);migrate_folio_undo_dst(dst, dst_locked, put_new_folio, private);return rc; }
try_to_migrate会将folio的pte改为swap pte,这样映射就解除了。
解除映射后就要将旧页的内容copy到新页了。路径是migrate_pages_batch->migrate_folio_move->move_to_new_folio->migrate_folio->migrate_folio_extra->folio_migrate_copy->folio_copy->copy_highpage->copy_page.
/* Migrate the folio to the newly allocated folio in dst. */ static int migrate_folio_move(free_folio_t put_new_folio, unsigned long private,struct folio *src, struct folio *dst,enum migrate_mode mode, enum migrate_reason reason,struct list_head *ret) {int rc;int old_page_state = 0;struct anon_vma *anon_vma = NULL;bool is_lru = !__folio_test_movable(src);struct list_head *prev;__migrate_folio_extract(dst, &old_page_state, &anon_vma);prev = dst->lru.prev;list_del(&dst->lru);//复制旧页到新页rc = move_to_new_folio(dst, src, mode);if (rc)goto out;if (unlikely(!is_lru))goto out_unlock_both;/** When successful, push dst to LRU immediately: so that if it* turns out to be an mlocked page, remove_migration_ptes() will* automatically build up the correct dst->mlock_count for it.** We would like to do something similar for the old page, when* unsuccessful, and other cases when a page has been temporarily* isolated from the unevictable LRU: but this case is the easiest.*/folio_add_lru(dst);if (old_page_state & PAGE_WAS_MLOCKED)lru_add_drain();if (old_page_state & PAGE_WAS_MAPPED)
//对dst重建映射remove_migration_ptes(src, dst, false);out_unlock_both:folio_unlock(dst);set_page_owner_migrate_reason(&dst->page, reason);/** If migration is successful, decrease refcount of dst,* which will not free the page because new page owner increased* refcounter.*/folio_put(dst);/** A folio that has been migrated has all references removed* and will be freed.*/list_del(&src->lru);/* Drop an anon_vma reference if we took one */if (anon_vma)put_anon_vma(anon_vma);folio_unlock(src);migrate_folio_done(src, reason);return rc; out:/** A folio that has not been migrated will be restored to* right list unless we want to retry.*/if (rc == -EAGAIN) {list_add(&dst->lru, prev);__migrate_folio_record(dst, old_page_state, anon_vma);return rc;}migrate_folio_undo_src(src, old_page_state & PAGE_WAS_MAPPED,anon_vma, true, ret);migrate_folio_undo_dst(dst, true, put_new_folio, private);return rc; }
复制完旧页后最重要的是重建新页的映射。
/** Get rid of all migration entries and replace them by* references to the indicated page.*/ void remove_migration_ptes(struct folio *src, struct folio *dst, bool locked) {struct rmap_walk_control rwc = {.rmap_one = remove_migration_pte,.arg = src,};if (locked)rmap_walk_locked(dst, &rwc);elsermap_walk(dst, &rwc); }