使用场景:做分类的,比如银行想做客户分类,看看新的这个客户,他是高风险用户还是低风险用户。
原理使用:可以用贝叶斯分类,决策树算法,还有KNN,本篇主要整理KNN。
KNN原理:有N个样本点,对新纪录r,使用KNN进行分类,看它属于哪个分类。具体如下:
1、先确定k值,不建议太大,一般采用交叉验证法决定,k值常见的为5、10。交叉验证法中,比较经典的,是k折交叉验证。k折交叉验证,既可以用来选择性能指标最好的模型,也可以用来确认在某一选定模型下,k值最合适的选择是什么。我们这里是找最合适的k值,具体来说,大概意思是,假设我们有一个数据集,其中包含12个样本,我们使用3折交叉验证(k=3),也就是把他们分成3个子集,每个子集4个样本。验证3次,每次选择其中一个作为验证集,其他2个是训练集。通过选定的模型(你可以理解为y=ax+b就是选定模型,通过训练集,你要确定a和b),依次对每个训练集数据测试,评估出这个模型下最合适的参数和拟合图,然后使用这个带有评估后参数的模型,在验证集中,再次进行性能指标的评估(准确率、精确度等)。验证次数为3次,然后取3次的平均值,就是此模型的平均准确率。对第一个k值的评估就结束了。然后继续用选定的模型,变化k,重复上面的操作,再次看验证集的性能指标。最后结合每个k具体的性能表现和稳定性(就是看性能表现的方差这些来评估),最终确定k;
2、以及判断距离的公式,一般是欧氏距离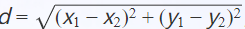
3、计算r和附近每个样本的距离d;
4、把d从小到大排序,取top k个最小的样本;
5、看看这k个样本里,属于多少个分类,哪个分类最多,说明新记录r,就是哪个分类的。
举例:如下,蓝色太阳,就是属于红色三角所在的分类。