尝试想要写自己的自动化测试框架,使用的是flask,想要使用SQLAlchemy实现数据库的模型映射,但是按照官方文档创建好module后执行时,会报错Working outside of application context.
经过一番查找,存在flask的上下文问题,以下是解决过程
官网案例:http://www.pythondoc.com/flask-sqlalchemy/quickstart.html#quickstart
# -*- coding = utf-8 -*-
# @File: main_f.py
from flask import Flask
from flask_sqlalchemy import SQLAlchemyapp = Flask(__name__)# 初始化数据库ORM连接
# 配置数据库链接地址
app.config["SQLALCHEMY_DATABASE_URI"] = run_config['database']['auto_test_db']['connect_uri']
# 若要查看映射的sql语句,需要如下配置,此功能对调试有用,正式环境建议设置为False
app.config['SQLALCHEMY_ECHO'] = True
db = SQLAlchemy(app)
# -*- codeing = utf-8 -*-
# @File : Users.py
from main import dbclass Users(db.Model):id = db.Column(db.Integer, primary_key=True)username = db.Column(db.String(80), unique=True)email = db.Column(db.String(120), unique=True)def __init__(self, username, email):self.username = usernameself.email = emaildef __repr__(self):return '<User %r>' % self.usernameif __name__ == '__main__':# 想要从定义好的模型中查询全量数据Users.query.all()
# -*- codeing = utf-8 -*-
# @Time :2024/6/19 18:32
# @Author :Ajie
# @Version :1.0
# @Descriptioon :
# @File : db_create.py
from DbORM.Users import Users
from main import db, app# 想要创建当前已经定义好的模型
db.create_all()
上述db_create.py和Users.py执行时都会报错
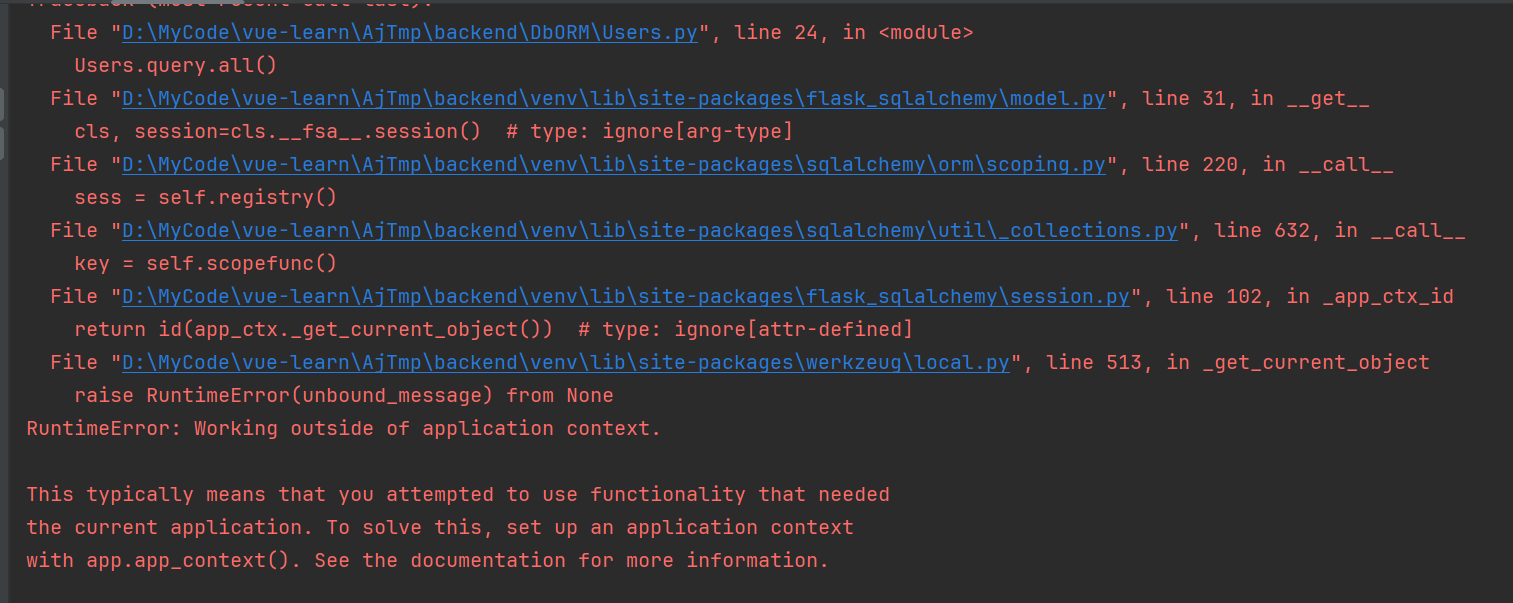
根据阅读和参考下面两篇文章得到解决
- https://blog.csdn.net/weixin_44285715/article/details/116839268
- https://cloud.tencent.com/developer/ask/sof/107343701
解决办法一:
根据代码中使用db的地点,使用with app.app_context()的方式携带flask上下文进行执行
# -*- codeing = utf-8 -*-
# @File : db_create.py
from DbORM.Users import Users
from main import db, appwith app.app_context():db.create_all()admin = Users('admin', 'admin@example.com')guest = Users('guest', 'guest@example.com')db.session.add(admin)db.session.add(guest)db.session.commit()
解决办法二:
直接在flask的启动文件中,人为添加flask上下文信息
# -*- coding = utf-8 -*-
# @File: main_f.py
from flask import Flask
from flask_sqlalchemy import SQLAlchemyapp = Flask(__name__)# 初始化数据库ORM连接
# 配置数据库链接地址
app.config["SQLALCHEMY_DATABASE_URI"] = run_config['database']['auto_test_db']['connect_uri']
# 若要查看映射的sql语句,需要如下配置,此功能对调试有用,正式环境建议设置为False
app.config['SQLALCHEMY_ECHO'] = True
db = SQLAlchemy(app)# 人为入栈,解决如创建数据库或数据表,或查询数据表时的上下文异常
app.app_context().push()
添加后即可在其他任意文件直接使用db