考试要求
- 了解切比雪夫不等式;
- 了解切比雪夫大数定律、伯努利大数定律和辛钦大数定律(独立同分布随机变量序列的大数定律);
- 了解棣莫弗-拉普拉斯定理(二项分布以正态分布为极限)和列维-林德伯格定理(独立同分布随机变量序列的中心极限定理)
1.1 马尔可夫和切比雪夫不等式
2.1.1 马尔可夫不等式
大部分概率不等式和界限背后的基本思想:通过少量和分布有关的信息,得到与 "extreme events" 相关的概率。extreme events 是指某个随机变量取很大的值时的事件;
例如,当我们只知道和期望有关的信息时,有如下结论, 当一个非负的随机变量的期望很小时,该随机变量取大值的概率也很小。 这就是马尔可夫不等式的基本思想,下面是马尔可夫不等式的公式,
当 \(X\) 的期望很小时,\(X\) 超过 \(a\) 值的概率也很小;如果 \(a\) 越来越大,那么 \(X\) 超过 \(a\) 值的概率就会越来越小。这就是马尔可夫不等式的内容。接下来看一下马尔可夫不等式的推导过程,
先求期望,以连续过程为例,离散过程也类似,只是积分变成了求和,\(PDF\) 变为了 \(PMF\);然后根据我们要证明的公式进行放缩,
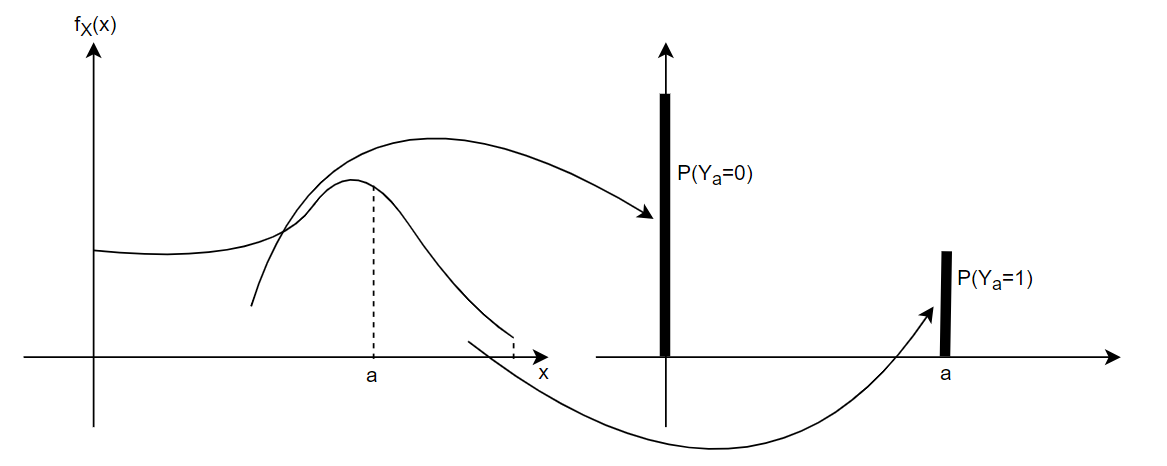
左图是非负随机变量 \(X\) 的概率密度函数,右图是与 \(X\) 相关的随机变量 \(Y_a\) 的分布列,分布列的构造如下,把 \(X\) 位于 \(0\) 和 \(a\) 之间的所有质量都赋予点 \(0\),大于等于 \(a\) 的质量都赋予点 \(a\),因为所有质量向左移,所以期望必然减少,因此,

由上图中的两个例子可以看出,马尔可夫不等式给出的上界与真实概率相差非常远,由此,引出下面的切比雪夫不等式,
5.1.2 切比雪夫不等式
从数学上来讲,切比雪夫不等式只是马尔可夫不等式的一个应用,但是其中包含了一些不同的信息;
切比雪夫不等式的主要内容是: 当一个随机变量的方差很小时,该随机变量的值距离期望很远的概率也很小 ;方差很小,意味着随机性很小,所以随机变量的值不会距离期望很远。因此有下述公式,
随机变量到期望的距离大于某个值的概率小于等于该随机变量的方差除以该值的平方。因此,方差很小时,远离均值的概率也很小;如果说 \(c\) 很大(即随机变量到均值的距离很大),那么概率就很小;
默认 \(c>0\),如果 \(c<0\),那么概率值恒为 \(1\),该界限值不能给我们提供任何信息,因为任何事件的概率都小于或等于 \(1\);
下面是切比雪夫不等式的证明过程,

切比雪夫不等式的应用,假设 \(c=k\sigma\),
当 \(k=3\) 时,\(P\left(|x-\mu|\geqslant 3\sigma\right)\leqslant \frac{1}{9}\),意味着随机变量偏离期望三个标准差的概率小于等于 \(\frac19\),该公式对于任何分布都成立;

如上图的指数随机变量,假设 \(a>1\),由切比雪夫不等式可得,\(P(X\geqslant a)\leqslant\frac{1}{(a-1)^2}\),马尔可夫不等式中得到的是 \(P(X\geqslant a)\leqslant\frac{1}{a}\),对于相同的 \(a\),我们总是能从切比雪夫不等式中得到更精确的上界。
与马尔可夫不等式相比,在大多数情况下,切比雪夫不等式可以得到更精确的上界,原因之一是因为切比雪夫不等式中使用到了和分布有关的更多信息(方差);
5.2 弱大数定理
弱大数定理是指独立同分布的随机变量序列的样本均值,在大样本的情况下,以很大的概率与随机变量的均值非常接近;
考虑 \(X_1,\,\,X_2,\,\,...,\,\,i.i.d\) 具有有限的 \(\mu\) 和 \(\sigma^2\),定义样本均值 \(M_n\) 为,
注意,样本均值也是一个随机变量,因为它是随机变量的函数,它与 \(\mu=E[X_i]\) 不同,后者指的是一个数,是随机变量 \(X_i\) 所有可能取值的均值。样本均值是用来估计试验真实均值的最简单、最自然的方法;
i.i.d 指 independent identically distribution,独立同分布
注意样本均值和试验真实的均值的区别:样本均值是一项长期实验中观察到的实验结果的平均值,而真实的均值是该试验中所有可能结果的平均值;我们的目的是要用观察到的试验结果的平均值来近似所有可能取值的均值。接下来计算一下样本均值作为一个随机变量所具有的一些特性。

从上述推导可以得到,样本均值的期望等于试验的真实期望;样本均值的方差为 \(\frac{\sigma^2}{n}\),由切比雪夫不等式可得,对于常数 \(\epsilon\) (一个固定的数),样本均值偏离真实均值超过 \(\epsilon\) 的概率小于等于 \(\frac{\sigma^2}{n\epsilon^2}\),随着 \(n\) 的增大,即试验次数的增加,样本均值偏离真实均值超过 \(\epsilon\) 的概率逐渐趋向于 \(0\);即随着 \(n\) 的增大,可以将样本均值近似为真实均值;这就是弱大数定理(WLLN,Weak Law of Large Number)的内容。

对弱大数定理的理解:从一个长期试验的角度出发,取一系列独立同分布的随机变量,每一个随机变量的值为 \(X_i = \mu+W_i\)(均值加一些噪音),噪音也是一个随机变量,所有的噪音都独立并且均值为 \(0\);
由此可以得到一系列独立同分布的包含噪音的取值,形成样本均值,利用弱大数定理可以得到,样本均值不可能离真实均值太远,当 \(n\) 足够大时,样本均值中的噪音的均值无限接近于它的真实均值 \(0\),这样我们就有足够的信心能相信样本均值非常接近真实的均值;
对于一个独立重复试验,该试验关联事件 \(A\),\(A\) 发生的概率为 \(p\),我们用 \(X_i\) 来表示事件 \(A\) 是否发生,\(1\) 为发生,\(0\) 为未发生,\(E[X_i] = p\);
在这个特定的实验中,样本均值为事件 \(A\) 发生的频率,将其称为事件 \(A\) 的经验频率 (empirical frequency) ,由弱大数定理可得,当试验次数很大时,经验频率将接近这个事件发生的概率,在这个例子中,它证明了将概率作为频率来解释;
选举问题
5.3 依概率收敛

对于弱大数定理,我们想说 \(M_n\) “收敛于” \(\mu\),那么如何定义“概率中的收敛呢”,上图中给出了定义,所以,对于弱大数定理等价于 \(M_n\) 依概率收敛于 \(\mu\)。

将数列收敛和依概率收敛进行比较,对于收敛的数列来说,是在某个值之后,所有的值都在某一个值的邻域内;而对于收敛的随机变量来说,随着 \(n\) 的增大,随机变量的 \(PMF/PDF\) 会集中分布在某数的邻域内。

如何证明上述性质
\(X_n\) 依概率收敛于 \(a\) 不能推出 \(E[X_n]\) 也收敛于 \(a\),下面是一个例子,

随机变量序列依概率收敛,不能推出这个序列的期望也依概率收敛。原因是因为概率收敛只取决于概率大的部分,而期望收敛同时取决于概率和随机变量的值的大小,图中的 \(n^2\) 虽然概率很小,但是随机变量的值很大,它对期望有很大的影响;

\(Y_n\) 取 \(X_i\) 中的最小值,因此,无论 \(n\) 如何变化,总有 \(Y_{n+1}\leqslant Y_n\),由此,可以推测 \(Y_n\) 依概率收敛于 \(0\),这也是求极限值的一般步骤,先找出一个可能的极限值,然后进行证明,由图中的证明过程可得 \(Y_n\) 依概率收敛于 \(0\);

Jensen's Inequality
Hoeffding's Inequality
5.4 中心极限定理

假设 \(X_i\) 的均值为 \(0\),范围在 \([-1,1]\) 之间的分布,如上图所示。则 \(S_n\) 的分布会随着 \(n\) 的增大而被拉的越来越宽。由弱大数定理可得,随着 \(n\) 的增大,\(M_n\) 的分布会逐渐趋向一点(均值),这种分布是退化的,最终会变成一点的概率。如何得到更有趣的极限分布呢?
当我们计算 \(\frac{S_n}{\sqrt n}\) 的方法时,可以发现,无论 \(n\) 如何变化,该随机变量的方差总是不变的,即分布分布本身可能会随着 \(n\) 的变化而变化,但分布的宽度总是一样的,它总是待在一个地方。当 \(n\to\infin\) 时,该分布会不会趋向于一个固定的形状?中心极限定理会给我们这个问题的答案。

中心极限定理与 \(\frac{S_n}{\sqrt n}\) 几乎类似,只不过,为了让方差为一,整体除了一个 \(\sigma\);还有一个问题,如果期望不为 \(0\),那么当 \(n\to\infin\) 分布集中的位置会随着 \(n\) 的变化而变化,它不会固定在一个位置,因此没有收敛的可能。为了让 \(\frac{S_n}{\sqrt n}\) 的方差为 \(1\)、期望为 \(0\),所以,中心极限定理的研究对象为:
中心极限定理的内容:取独立同分布的随机变量序列的总和,然后将其标准化(使期望为 \(0\),方差为 \(1\)),当样本数趋向于无穷大的时候,标准化后的总和的分布函数收敛于标准正态的分布函数。即\(Z_n\) 的分布依概率收敛于标准正态分布。

中心极限定理非常重要。因为以下原因:
- 其一是它具有通用性,它不关心 \(X_i\) 的分布是什么,只要处于极限情况下,它们的和总是表现为一个正态分布;还有就是它的应用很方便,当我们应用到一个特定的问题或模型中时,只需要知道它的期望和方差即可;
- 提供了一种简单的计算方法。当我们知道 \(X_i\) 详细的分布时,如果想要计算 \(S_n\),可以对 \(X_i\) 做 \(n\) 次卷积,也可以使用中心极限定理进行计算,后者的计算过程更为简单;
- 从理论上看,该定理表明当大样本的独立随机变量序列的和大致是正态的,所以当人们遇到的随机变量是由许多影响小但是独立的随机变量的总和时,此时根据中心极限定理可判定这个随机变量的分布是正态的;

中心极限定理的应用:(基于中心极限定理的近似)
中心极限定理允许我们将 \(Z_n\) 的分布近似为正态分布,从而可以计算与 \(Z_n\) 相关的随机变量的概率问题。因为 \(S_n\) 是关于 \(Z_n\) 的线性函数,所以 \(S_n\) 也可近似为正态分布,由 \(S_n\) 和 \(Z_n\) 的公式可以得到 \(S_n\) 的均值和方差,由此可以推出 \(S_n\) 的近似的分布函数。
中心极限定理要在 \(n\) 很大的时候才能成立,多大算大?如果 \(n\) 适中,可以使用中心极限定理吗?
当 \(n\) 的值适中时,中心极限定理可能得到很好的近似,也有可能得到较差的近似。如果 \(X_i\) 的分布与正态分布比较相似,对于较小的 \(n\) 值也可以得到较好的近似;当 \(X_i\) 的分布具有对称性或单峰,对形成较好的近似也有帮助。

利用中心极限定理求概率,大致可分为上述四类问题,它们都可总结为一类问题,就是对于 \(P(S_n\leqslant a)\approx b\) 中的参数 \(n,\,\,a,\,\,b\) 已知其中两个的情况下求第三个参数。第四类问题为隐含的使用中心极限定理求概率的问题。

中心极限定理的一个重要应用就是近似二项分布。二项分布可看作 \(n\) 个伯努利随机变量的和,即 \(S_n = X_1 + \cdots+X_n\),因此可以使用中心极限定理求概率。但是直接求的精确度并不高,比如下面的 \(P(S_n\leqslant 21)\) 直接使用 \(CLT\) 进行求值发现比实际值低四个百分点。因为 \(S_n\) 的取值为整数,所以有 \(P(S_n\leqslant 21) = P(S_n<22)\),利用 \(CLT\) 进行求值可得 \(P(S_n<22)=0.9082\) 比实际值要高了三个百分点。所以,\(P(S_n\leqslant 21)\) 的值应该在 \(21\) 和 \(22\) 之间的某个数,我们一般取中点,即用 \(P(S_n\leqslant 21.5)\) 来近似 \(P(S_n\leqslant 21)\)。

从上面的例子可以发现,在求二项分布的概率时,用二项分布对应的正态分布的中点值可以得到很好的近似,下面尝试使用这个中点值求二项分布某点处的概率。

选举问题