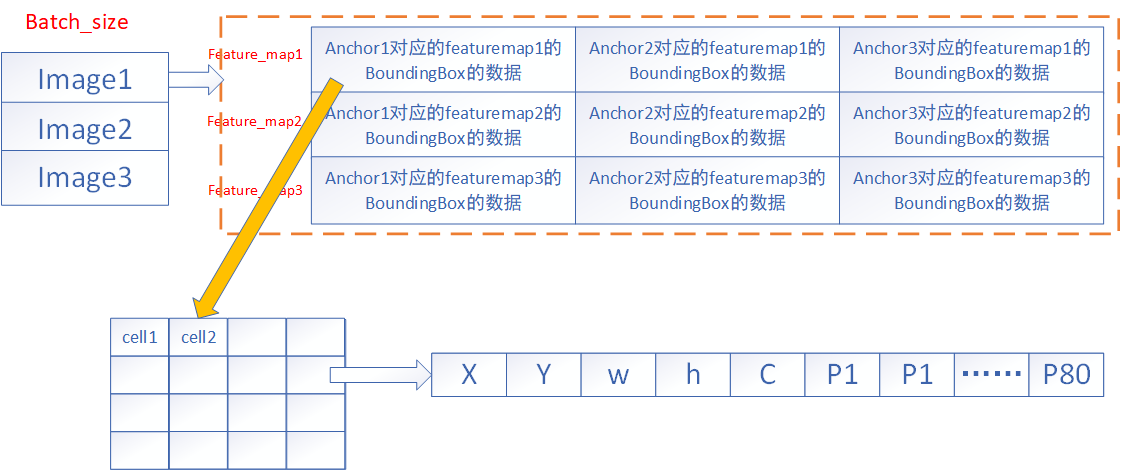
yolov5内存分布分析
Transpose输出分析
假设batch_size为1,yolov5有三个输出,shape分别是:
- (1,3,80,80,85)
- (1,3,40,40,85)
- (1,3,20,20,85)
其中3代表anchor数量,20*20代表feature_map大小,85代表boundbox的(x,y,w,h,c+80个类别的概率)
其中(x,y,w,h,c+80个类别的概率)在内存中是连续分布的,即:

(1,3,20,20,85)整个数组在内存分布中也是连续分布的,
- (0,0,0,0,0)->x->第一个anchor在第一个cell对应的boundingbox的x
- (0,0,0,0,1)->y->第一个anchor在第一个cell对应的boundingbox的y
- (0,0,0,0,2)->w->第一个anchor在第一个cell对应的boundingbox的w
- (0,0,0,0,3)->h->第一个anchor在第一个cell对应的boundingbox的h
- ......
- (0,0,0,1,0)->x->第一个anchor在第二个cell对应的boundingbox的x
- (0,0,0,1,1)->y->第一个anchor在第二个cell对应的boundingbox的y
- (0,0,0,1,2)->w->第一个anchor在第二个cell对应的boundingbox的w
- (0,0,0,1,3)->h->第一个anchor在第二个cell对应的boundingbox的h
- ......
- (0,1,0,0,0)->x->第二个anchor在第一个cell对应的boundingbox的x
- (0,1,0,0,1)->y->第二个anchor在第一个cell对应的boundingbox的y
- (0,1,0,0,2)->w->第二个anchor在第一个cell对应的boundingbox的w
- (0,1,0,0,3)->h->第二个anchor在第一个cell对应的boundingbox的h
即:
后处理代码分析
# 从第一个anchor开始获取
for (int q = 0; q < num_anchors; q++){const float anchor_w = anchors[q * 2];const float anchor_h = anchors[q * 2 + 1];const ncnn::Mat feat = feat_blob.channel(q);#从第一个cell开始获取for (int i = 0; i < num_grid_y; i++){for (int j = 0; j < num_grid_x; j++){const float* featptr = feat.row(i * num_grid_x + j);#第5个是box_confidence值,需要使用sigmoid函数求值float box_confidence = sigmoid(featptr[4]);if (box_confidence >= prob_threshold){# 之所以这么写是因为可以减少sigmoid(class_score)的次数,sigmoid较为耗时#find class index with max class scoreint class_index = 0;float class_score = -FLT_MAX;for (int k = 0; k < num_class; k++){# box_confidence之后是每个类别的概率float score = featptr[5 + k];if (score > class_score){class_index = k;class_score = score;}}#论文规定float confidence = box_confidence * sigmoid(class_score);if (confidence >= prob_threshold){# 依次获取x,y,w,hfloat dx = sigmoid(featptr[0]);float dy = sigmoid(featptr[1]);float dw = sigmoid(featptr[2]);float dh = sigmoid(featptr[3]);# 其余部分省略,可以参考ncnn代码.......}}}}}
====================================================================================
Conv输出分析
NPU对算法进行加速处理时,shape算子,如reshape、transpose通常不支持加速,有两种解决方法,
- 使用C/C++语言重新实现reshape、transpose算子功能,使用CPU进行处理(待完善)
- 直接按照conv层的输出内存分布获取数据进行处理
假设batch_size为1,卷积层的输出shape为:
- (1,255,80,80)
- (1,255,40,40)
- (1,255,20,20)
其中255表示3*85,3代表anchor数量,,85代表boundbox的(x,y,w,h,c+80个类别的概率),20x20代表feature_map大小。
其中(x,y,w,h,c+80个类别的概率)在内存中是连续分布的,即:

(1,255,20,20)整个数组在内存分布中也是连续分布的,
-
(0,0,0,0)->x->第一个anchor在第一个cell对应的boundingbox的x
-
(0,0,0,1)->x->第一个anchor在第二个cell对应的boundingbox的x
-
(0,0,0,2)->x->第一个anchor在第三个cell对应的boundingbox的x
-
......
-
(0,1,0,0)->x->第一个anchor在第一个cell对应的boundingbox的y
-
(0,1,0,1)->x->第一个anchor在第二个cell对应的boundingbox的y
-
(0,1,0,2)->x->第一个anchor在第三个cell对应的boundingbox的y
-
......
-
(0,85,0,0)->x->第一个anchor在第一个cell对应的boundingbox的y
-
(0,85,0,1)->x->第二个anchor在第二个cell对应的boundingbox的y
-
(0,85,0,2)->x->第二个anchor在第三个cell对应的boundingbox的y
-
....
即:

后处理代码分析
# 从第一个cell开始
for(int shiftY = 0; shiftY < gridY; shiftY++){for(int shiftX = 0; shiftX < gridX; shiftX++){# 从第一个anchor开始for(int i = 0; i < 3; i++){pRecord = pMatData[i];# 获取当前cellint pindex = shiftY* gridX + shiftX;# coordindex的坐标对应xint coordindex = pindex;# 指针移动到ypindex = pindex + gridX * gridY;# 指针移动到wpindex = pindex + gridX * gridY;# 指针移动到hpindex = pindex + gridX * gridY;# 指针移动到Cpindex = pindex + gridX * gridY;# 获取C的值float precord4 = sigmoid(pRecord[pindex]);# 指针移动到Ppindex = pindex + gridX * gridY ;for (cls = 0; cls < classNum; cls++){#获取P的值float precord5 = sigmoid(pRecord[pindex]);#指针移动到P1pindex = pindex + gridX * gridY;score = precord5 * precord4;if (score > gYolov7Para.confidenceThreshold){//大于设置的阈值# 获取xfloat precord0 = sigmoid(pRecord[coordindex]);coordindex = coordindex + gridX * gridY;# 获取y float precord1 = sigmoid(pRecord[coordindex]);coordindex = coordindex + gridX * gridY;# 获取w float precord2 = sigmoid(pRecord[coordindex]);coordindex = coordindex + gridX * gridY;# 获取h float precord3 = sigmoid(pRecord[coordindex]);coordindex = coordindex + gridX * gridY;# 其余部分省略.......}}}}}