arena

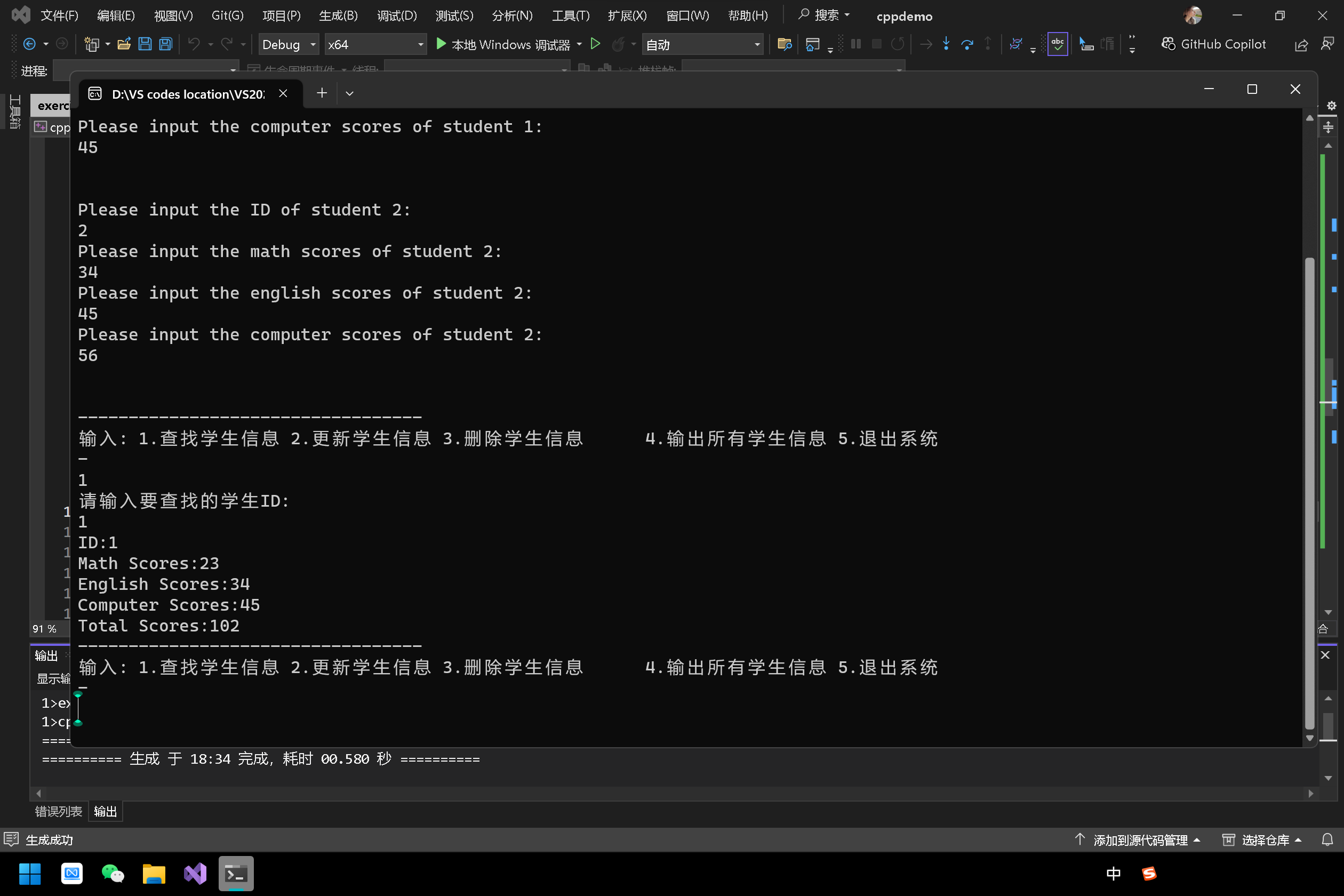
chunk

通俗地说,一块由分配器分配的内存块叫做一个 chunk,包含了元数据和用户数据。具体一点,chunk 完整定义如下:
struct malloc_chunk {INTERNAL_SIZE_T mchunk_prev_size; /* Size of previous chunk (if free). */INTERNAL_SIZE_T mchunk_size; /* Size in bytes, including overhead. */struct malloc_chunk* fd; /* 这两个指针只在free chunk存在 */struct malloc_chunk* bk;/* 只在large bin 存在. */struct malloc_chunk* fd_nextsize; /* double links -- used only if free. */struct malloc_chunk* bk_nextsize;
};typedef struct malloc_chunk* mchunkptr;
这里出现的6个字段均为元数据。
Allocated chunk

第一个部分(32 位上 4B,64 位上 8B)叫做prev_size,只有在前一个 chunk 空闲时才表示前一个块的大小,否则这里就是无效的,可以被前一个块征用(存储用户数据)。
这里的前一个chunk,指内存中相邻的前一个,而不是freelist链表中的前一个。
PREV_INUSE代表的“前一个chunk”同理。
第二个部分的高位存储当前 chunk 的大小,低 3 位分别表示:
- P: 之前的 chunk 已经被分配则为 1,
- M: 当前 chunk 是
mmap()得到的则为 1 - N:
NON_MAIN_ARENA当前 chunk 在non_main_arena里则为 1
你可能会有几个困惑:
-
fd、bk、fd_nextsize、bk_nextsize这几个字段去哪里了?
对于已分配的 chunk 来说它们没用,所以也被征用了,用来存储用户数据。 -
为什么第二个部分的低 3 位就这么被吞了而不会影响
size?
这是因为malloc会将用户申请的内存大小转化为实际分配的内存,以此来满足(至少)8字节对齐的要求,同时留出额外空间存放 chunk 头部。由于(至少)8字节对齐了,低3位自然就没用了。在获取真正的size时,会忽略低3位:
/*Bits to mask off when extracting sizeNote: IS_MMAPPED is intentionally not masked off from size field inmacros for which mmapped chunks should never be seen. This shouldcause helpful core dumps to occur if it is tried by accident bypeople extending or adapting this malloc.*/
#define SIZE_BITS (PREV_INUSE | IS_MMAPPED | NON_MAIN_ARENA)/* Get size, ignoring use bits */
#define chunksize(p) ((p)->size & ~(SIZE_BITS))
malloc是如何将申请的大小转化为实际分配的大小的呢?
核心在于request2size宏:
/* pad request bytes into a usable size -- internal version */#define request2size(req) \(((req) + SIZE_SZ + MALLOC_ALIGN_MASK < MINSIZE) ? \MINSIZE : \((req) + SIZE_SZ + MALLOC_ALIGN_MASK) & ~MALLOC_ALIGN_MASK)
其中用到的其它宏定义:
# define MALLOC_ALIGNMENT (2 *SIZE_SZ)/* The corresponding bit mask value */
#define MALLOC_ALIGN_MASK (MALLOC_ALIGNMENT - 1)/* The smallest possible chunk */
#define MIN_CHUNK_SIZE (offsetof(struct malloc_chunk, fd_nextsize))/* The smallest size we can malloc is an aligned minimal chunk */
#define MINSIZE \(unsigned long)(((MIN_CHUNK_SIZE+MALLOC_ALIGN_MASK) & ~MALLOC_ALIGN_MASK))
- 这里还有一个
mem指针,是做什么用的?
这是调用malloc时返回给用户的指针。实际上,真正的chunk 是从chunk指针开始的。
/* The corresponding word size */
#define SIZE_SZ (sizeof(INTERNAL_SIZE_T))/* conversion from malloc headers to user pointers, and back */#define chunk2mem(p) ((void*)((char*)(p) + 2*SIZE_SZ))
#define mem2chunk(mem) ((mchunkptr)((char*)(mem) - 2*SIZE_SZ))
- 用户申请的内存大小就是用户数据可用的内存大小吗?
不一定,原因还是字节对齐问题。要获得可用内存大小,可以用malloc_usable_size()获得,其核心函数是:
static size_t
musable (void *mem)
{mchunkptr p;if (mem != 0){p = mem2chunk (mem);if (__builtin_expect (using_malloc_checking == 1, 0))return malloc_check_get_size (p);if (chunk_is_mmapped (p))return chunksize (p) - 2 * SIZE_SZ;else if (inuse (p))return chunksize (p) - SIZE_SZ;}return 0;
}
Free chunk

首先,prev_size必定存储上一个块的用户数据,因为 Free chunk 的上一个块必定是 Allocated chunk,否则会发生合并。
接着,多出来的fd指向同一个 bin 中的前一个 Free chunk,bk指向同一个 bin 中的后一个 Free chunk。
这里提到了 bin,我们将在后面介绍。
此外,对于 large bins 中的 Free chunk,fd_nextsize与bk_nextsize会生效,分别指向 large bins 中前一个(更大的)和后一个(更小的)空闲块。
Top chunk
一个arena顶部的 chunk 叫做 Top chunk,它不属于任何 bin。当所有 bin 中都没有空闲的可用 chunk 时,我们切割 Top chunk 来满足用户的内存申请。假设 Top chunk 当前大小为 N 字节,用户申请了 K 字节的内存,那么 Top chunk 将被切割为:
- 一个 K 字节的 chunk,分配给用户
- 一个 N-K 字节的 chunk,称为 Last Remainder chunk
后者成为新的 Top chunk。如果连 Top chunk 都不够用了,那么:
- 在
main_arena中,用brk()扩张 Top chunk - 在
non_main_arena中,用mmap()分配新的堆
注:Top chunk 的 PREV_INUSE 位总是 1
Last Remainder chunk
当需要分配一个比较小的 K 字节的 chunk 但是 small bins 中找不到满足要求的,且 Last Remainder chunk 的大小 N 能满足要求,那么 Last Remainder chunk 将被切割为:
- 一个 K 字节的 chunk,分配给用户
- 一个 N-K 字节的 chunk,成为新的 Last Remainder chunk
它的存在使得连续的小空间内存申请,分配到的内存都是相邻的,从而达到了更好的局部性。

bins

fastbins

small bins
small bins 中一共有 62 个循环双向链表,每个链表中存储的 chunk 大小都一致。比如对于 32 位系统来说,下标 2 对应的双向链表中存储的 chunk 大小为均为 16 字节。每个链表都有链表头结点,这样可以方便对于链表内部结点的管理。此外,small bins 中每个 bin 对应的链表采用 FIFO 的规则,所以同一个链表中先被释放的 chunk 会先被分配出去。
或许,大家会很疑惑,那 fastbin 与 small bin 中 chunk 的大小会有很大一部分重合啊,那 small bin 中对应大小的 bin 是不是就没有什么作用啊? 其实不然,fast bin 中的 chunk 是有可能被放到 small bin 中去的,我们在后面分析具体的源代码时会有深刻的体会。
unsorted bins

large bins

malloca过程



free过程

tcache机制
范围:最大0x410,之后放入unsortbin
在GLIBC2.26中,引入了一种新的bins,他类似于fastbin,但是每条链上最多可以有7个chunk,free的时候当tcache满了才放入fastbin,unsorted bin,malloc的时候优先去tcache找。
换句话说. tcache是比fastbin优先级更高范围更大的一类bins
对于tcache来说,他的free范围变大了,也就是说我们直接free一块unsorted bin大小的chunk,并不会直接进入unsorted bin而是会先进入tcache,只有对应大小的tcache满了以后,才会放入unsorted bin。
这时想要得到一个unsorted bin有以下方法:
1.free一个largebin,largebin不会放入tcache
2.先连续free填满tcache,再free放进unsorted bin
3.(2.31以后因为更新不可用)在存有uaf的时候,可以先连续free两次,再malloc三次快速填满tcache。这时因为tcache的个数是由count代表的,每申请一次就会-1且申请时并不判断count,先free两次造成double free,令next始终指向自身,这时count为2,再连续申请3次,count变为-1,而在比较时是char类型,也就是unsigned int8,-1远大干7,导致tcache认为已满
4.打tcache_pthread_struct修改count后free

glibc堆中的检测机制发展
可从例题了解http://t.csdnimg.cn/rO3Xq
glibc2.23
1.size位检测:fastbin会检测size位是否为空因此需要伪造chunk(反制手段(__malloc_hook - 0x23))
2.double free:glibc2.23对于double free的管理非常地松散,如果连续释放相同chunk的时候,会报错,但是如果隔块释放的话,就没有问题。
glibc2.27
1.自此后引入tchache机制由于tcache不检查size位,也不检查FD,只要泄露了地址,加上UAF就能实现任意申请。
2.double free:加强了对use after free的检测,所以glibc2.23中针对fastbin的uaf在glibc2.27以后,就失效了。glibc2.27—ubuntu4加入了tchache的double free检测
glibc2.31
1.会检查tcache的数量是否正确,要想连续add两次,就必须有两个chunk在tcache中
glibc2.32
1.堆指针异或加密(只有tcache和fastbin)safe-linking

2.Tcache地址对齐检查:tcache或者fastbin指向的chunk指针的最后一位必须是0(64位下),不能是8。tcache不能任意申请了
glibc2.35
1.从2.34开始取消了hook机制,堆题要开始堆栈结合