1、attention机制:这算是transformer架构最大的创新点了!利用attention机制,找到token之间的相似度(或则说距离),根据相似度调整token本身的embedding值,本质就是根据token的context调整自身的embedding值,这个思路非常符合人脑对语言和语义的理解!比如”苹果“这个词,如果只看这一个token,没有任何context,根本无法分辨是水果还是手机,此时该token的embedding大概率是没法用的!但是有了context就不一样了,比如:
- 苹果、香蕉、梨、菠萝这些水果中,我最喜欢的是菠萝! 很明显,这里的苹果是水果,V向量中水果相关的维度值会比较大,其他维度值会较小!
- 苹果的内存128G,屏幕耐磨不易坏;电池续航8小时,上班时间不用充电! 很明显,这里的苹果是电子产品,V向量中电子产品相关的维度值会比较大,其他维度值会较小!
具体做法也不复杂:Q和K相乘得到权重值,用权重值乘以V向量(V向量才是token最终的embedding值)!这里打个岔:目前大模型微调最主流的就是Lora了,思路是用low rank矩阵旁路主矩阵,通过旁路矩阵吸收和承载新数据的信息!理论上讲:transformer架构中只要有矩阵的地方,都可以旁路low rank矩阵;但如果真这么做,计算量会很大(算力足够的土豪当然可以每个原矩阵都旁路啦)!为了保证效果,可以优先考虑Q和K矩阵,通过这两个矩阵提取新微调数据的context信息,然后调整token原有的V值!
在llama的attention代码中哟三个大:LlamaAttention、LlamaFlashAttention2、LlamaSdpaAttention,LlamaAttention是基础类,实现了transformer的attention机制,另外两个是基于LlamaAttention做了改进。、
(1)FlashAttention2:参考官网:https://github.com/Dao-AILab/flash-attention ; 从名字就能看出来主要改进点是flash(Fast and Memory-Efficient Exact Attention with IO-Awareness)! 核心的改进代码如下:
- _upad_input 方法:对输入 tensor 进行 unpad 操作来去除填充 token,减少attention计算时内积的计算量,并生成相应的索引数组和 cumulated sequence lengths;
#去掉padding的token,节约attention时的算力和时间def _upad_input(self, query_layer, key_layer, value_layer, attention_mask, query_length):indices_k, cu_seqlens_k, max_seqlen_in_batch_k = _get_unpad_data(attention_mask)batch_size, kv_seq_len, num_key_value_heads, head_dim = key_layer.shape#使用索引操作 index_first_axis 来避免不必要的内存复制,减少IOkey_layer = index_first_axis(key_layer.reshape(batch_size * kv_seq_len, num_key_value_heads, head_dim), indices_k) # 重新排列,允许对输入进行分块处理,减少内存占用value_layer = index_first_axis(value_layer.reshape(batch_size * kv_seq_len, num_key_value_heads, head_dim), indices_k)# 重新排列,允许对输入进行分块处理,减少内存占用if query_length == kv_seq_len:query_layer = index_first_axis(query_layer.reshape(batch_size * kv_seq_len, self.num_heads, head_dim), indices_k)# 重新排列,允许对输入进行分块处理,减少内存占用cu_seqlens_q = cu_seqlens_kmax_seqlen_in_batch_q = max_seqlen_in_batch_kindices_q = indices_kelif query_length == 1:max_seqlen_in_batch_q = 1cu_seqlens_q = torch.arange(batch_size + 1, dtype=torch.int32, device=query_layer.device) # There is a memcpy here, that is very bad.indices_q = cu_seqlens_q[:-1]query_layer = query_layer.squeeze(1)else:# The -q_len: slice assumes left padding.attention_mask = attention_mask[:, -query_length:]query_layer, indices_q, cu_seqlens_q, max_seqlen_in_batch_q = unpad_input(query_layer, attention_mask)return (query_layer,key_layer,value_layer,indices_q,(cu_seqlens_q, cu_seqlens_k),(max_seqlen_in_batch_q, max_seqlen_in_batch_k),)
-
_flash_attention_forward:核心还是调用了flash_attn包的flash_attn_varlen_func方法:
def _flash_attention_forward(self, query_states, key_states, value_states, attention_mask, query_length, dropout=0.0, softmax_scale=None):""" 先去掉padding 的token再计算attention,然后再pad回去还原Calls the forward method of Flash Attention - if the input hidden states contain at least one padding tokenfirst unpad the input, then computes the attention scores and pad the final attention scores.Args:query_states (`torch.Tensor`):Input query states to be passed to Flash Attention APIkey_states (`torch.Tensor`):Input key states to be passed to Flash Attention APIvalue_states (`torch.Tensor`):Input value states to be passed to Flash Attention APIattention_mask (`torch.Tensor`):The padding mask - corresponds to a tensor of size `(batch_size, seq_len)` where 0 stands for theposition of padding tokens and 1 for the position of non-padding tokens.dropout (`float`):Attention dropoutsoftmax_scale (`float`, *optional*):The scaling of QK^T before applying softmax. Default to 1 / sqrt(head_dim)"""if not self._flash_attn_uses_top_left_mask:causal = self.is_causalelse:# TODO: Remove the `query_length != 1` check once Flash Attention for RoCm is bumped to 2.1. For details, please see the comment in LlamaFlashAttention2 __init__.causal = self.is_causal and query_length != 1# Contains at least one padding token in the sequenceif attention_mask is not None:batch_size = query_states.shape[0]query_states, key_states, value_states, indices_q, cu_seq_lens, max_seq_lens = self._upad_input( #先去掉padding query_states, key_states, value_states, attention_mask, query_length)cu_seqlens_q, cu_seqlens_k = cu_seq_lensmax_seqlen_in_batch_q, max_seqlen_in_batch_k = max_seq_lens#自动处理 softmax 的计算,并在计算过程中忽略不必要的填充 tokenattn_output_unpad = flash_attn_varlen_func(query_states,key_states,value_states,cu_seqlens_q=cu_seqlens_q,cu_seqlens_k=cu_seqlens_k,max_seqlen_q=max_seqlen_in_batch_q,max_seqlen_k=max_seqlen_in_batch_k,dropout_p=dropout,softmax_scale=softmax_scale,causal=causal,)#attention计算完成后,重新padattn_output = pad_input(attn_output_unpad, indices_q, batch_size, query_length)else:attn_output = flash_attn_func(query_states, key_states, value_states, dropout, softmax_scale=softmax_scale, causal=causal)return attn_output
flash_attn_varlen_func核心的优化思路:
- 索引和序列长度累加器:使用索引数组和累加的序列长度数组来表示变长序列。这些数组允许函数仅对有效的非填充(non-padded)部分进行计算,从而避免了填充 token 的冗余计算
- 逐步计算(Chunk-Based Computation):将输入序列分割成较小的块,每次只对一个块进行计算。这种方法不仅减少了内存使用,还能更好地利用缓存,提高计算效率
- 并行计算:充分利用 GPU 的并行计算能力,通过优化的内核实现并行执行矩阵乘法和 softmax 操作。这些优化内核能够最大限度地利用 GPU 的计算资源,减少计算时间
- 优化的 softmax 计算:通过自定义的内核实现高效的 softmax 计算,避免了数值不稳定性(减去向量的最大值避免underflow和overflow),并且能更快地完成 softmax 操作。
2、5个model,从名字就能猜出来这5个model的作用:
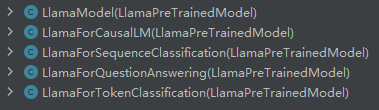
既然功能不同,代码肯定不同,每种model的核心代码如下:
- LlamaModel:实现了基本的transformer架构,但并不包括实现特定功能的lm_head!
class LlamaModel(LlamaPreTrainedModel):def __init__(self, config):super().__init__(config)self.transformer = Transformer(config)self.init_weights()def forward(self, input_ids, attention_mask=None):outputs = self.transformer(input_ids, attention_mask=attention_mask)return outputs
- LlamaForCausalLM:使用的自回归auto regression,下一个token就是target,采用cross enctropy的loss计算;
class LlamaForCausalLM(LlamaPreTrainedModel):def __init__(self, config):super().__init__(config)self.llama = LlamaModel(config)self.lm_head = nn.Linear(config.hidden_size, config.vocab_size, bias=False)self.init_weights()def forward(self, input_ids, attention_mask=None, labels=None):transformer_outputs = self.llama(input_ids, attention_mask=attention_mask)hidden_states = transformer_outputs[0]logits = self.lm_head(hidden_states)loss = Noneif labels is not None:loss_fct = CrossEntropyLoss()loss = loss_fct(logits.view(-1, self.config.vocab_size), labels.view(-1))return (loss, logits) if loss is not None else logits
LlamaForSequenceClassification:用于序列级别分类任务。
class LlamaForSequenceClassification(LlamaPreTrainedModel):def __init__(self, config):super().__init__(config)self.num_labels = config.num_labelsself.llama = LlamaModel(config)self.classifier = nn.Linear(config.hidden_size, config.num_labels)self.init_weights()def forward(self, input_ids, attention_mask=None, labels=None):transformer_outputs = self.llama(input_ids, attention_mask=attention_mask)hidden_states = transformer_outputs[0]logits = self.classifier(hidden_states[:, 0, :]) # Use the CLS token hidden state loss = Noneif labels is not None:loss_fct = CrossEntropyLoss()loss = loss_fct(logits.view(-1, self.num_labels), labels.view(-1))return (loss, logits) if loss is not None else logits
LlamaForQuestionAnswering:用于问答任务。添加了一个问答头,包括两个线性层,用于预测答案的起始位置和结束位置。
class LlamaForQuestionAnswering(LlamaPreTrainedModel):def __init__(self, config):super().__init__(config)self.llama = LlamaModel(config)self.qa_outputs = nn.Linear(config.hidden_size, 2)self.init_weights()def forward(self, input_ids, attention_mask=None, start_positions=None, end_positions=None):transformer_outputs = self.llama(input_ids, attention_mask=attention_mask)hidden_states = transformer_outputs[0]logits = self.qa_outputs(hidden_states)start_logits, end_logits = logits.split(1, dim=-1)start_logits = start_logits.squeeze(-1)end_logits = end_logits.squeeze(-1)loss = Noneif start_positions is not None and end_positions is not None:loss_fct = CrossEntropyLoss()start_loss = loss_fct(start_logits, start_positions)end_loss = loss_fct(end_logits, end_positions)loss = (start_loss + end_loss) / 2return (loss, start_logits, end_logits) if loss is not None else (start_logits, end_logits)
LlamaForTokenClassification:用于标记级别分类任务。加了一个标记分类头,用于每个输入标记生成类别标签class LlamaForTokenClassification(LlamaPreTrainedModel):def __init__(self, config):super().__init__(config)self.num_labels = config.num_labelsself.llama = LlamaModel(config)self.classifier = nn.Linear(config.hidden_size, config.num_labels)self.init_weights()def forward(self, input_ids, attention_mask=None, labels=None):transformer_outputs = self.llama(input_ids, attention_mask=attention_mask)hidden_states = transformer_outputs[0]logits = self.classifier(hidden_states)loss = Noneif labels is not None:loss_fct = CrossEntropyLoss()loss = loss_fct(logits.view(-1, self.num_labels), labels.view(-1))return (loss, logits) if loss is not None else logits
以上各种model的作用不同,但实现的原理没有本质区别:先把hidden_states通过矩阵相乘的方式做线性变换,映射到新的空间,然后再在新的空间做各种操作!
3、旋转位置编码
(1)NLP任务中,token的位置是非常重要的,比如”我打小明“和”小明打我“,这两句话的token完全相同,但整体的语义截然相反!传统的RNN和LSTM因为是顺序处理每个词,所以能很好地理解词的位置,但transformer架构就不一样了:为了提升效率,底层计算的时候是并行计算的,所以embedding需要包含位置信息,避免语义出错!此外,token位置信息应该是相对位置信息,不能用绝对位置信息,同样举例:”我打小明“ 和 ”昨天下午在公司,我把小明打了一顿“ ,这两句话的语义是一样的,主题都是我打小明,但第二句话中关键token的绝对位置信息完全不同,如果embedding中用绝对位置信息,可能会影响最终的语义理解,需要用相对位置信息!最终的理想结果应该是:我 打 小明 这个三个token的qk内积在第一个短句的结果,和在第二个长句的结果应该是接近甚至一样的,就说明绝对位置不影响整体的语义信息啦(这也是个取其精华、去其糟粕的过程)!所以终极问题来了:这个相对位置编码应该怎么求?
(2)详细的推导过程参考:https://wmathor.com/index.php/archives/1542/ 直接上结论,以二维为例,如下:
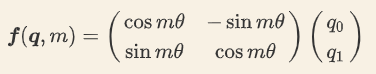
其中m就是token在sequence中的绝对位置,seta是频率超参,计算时人为指定的,不是学习得来!位置m的token和位置n的token的q、k相乘就变成了:
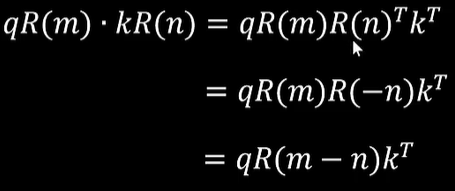
R是旋转矩阵。原始的q和k内积之前,先通过旋转矩阵换个位置,分别把自己的绝对位置m、n信息融入,结果中的R(m-n)不就把两个token的相对位置信息包括进去了么?
上面的embedding是2位的,但实际embedding肯定不止二维,咋办了?因为内积满足线性叠加性,因此任意偶数维的 RoPE,我们都可以表示为二维情形的拼接,如下:
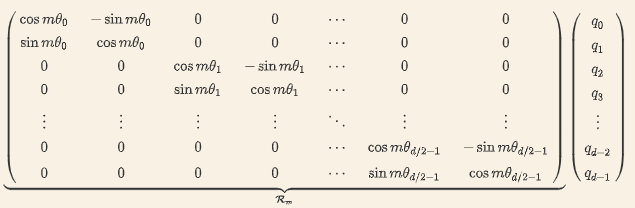
每两个维度分成一组,每组单独计算,q的每个维度都能包含位置信息啦!计算时只剩最后1个问题了:seta是超参数,不是学习的来的,而是计算时人为指定的,那么这个seta该怎么设置才合理?
(3)”我打小明“、”昨天下午在公司,我把小明打了一顿“、”我昨天下午在公司把小明狠狠地按在地上打了一顿“,这3句话的语义是一样的,都是我打了小明,核心token就3个:我 小明 打;理论上讲,3个token的q和k应该比较接近才合理!但实际情况是:这3个token在3句话中位置(不论绝对位置,还是相对位置)差异都较大,怎么能在这3个句子中都能正确地反映相对位置依赖信息了?
以 llama为例,假设模型的隐藏层维度是d=1024,那么可以选择的 seta 值会覆盖从较低频率到较高频率的范围,如下:
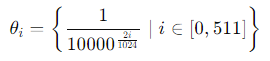
这意味着在 1024 维空间中,会有 512 对不同频率的正弦和余弦函数,分别应用在不同的维度对上;具体的数值列举如下:
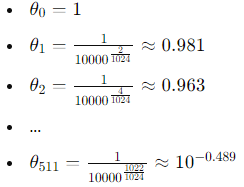
有没有发现一个规律啊:seta的值随着维度增加越来越小了!seta值越小,频率越低,波长越长,正余弦在较长的序列范围内变化较慢,在整个序列中可能只有几次完整的波动,这种缓慢的变化允许长波长函数能够平滑地跨越整个序列,捕捉到远距离的位置关系,保持一定的稳定性。因此,低频(长波长)的编码在捕捉到句子整体的结构和主旨上比较有效;反之:seta值越大,频率越高,波长越短,正弦余弦函数在整个序列中完成多次波动,能更好地提取局部语义信息!
上面的描述可能有点抽象,这里举个具体的例子说明:假设我们有一个长度为 L=100 的序列,我们选取低频和高频维度的正弦函数来进行位置编码。
参数设定
- 序列长度 L=100
- 向量维度 d=128
- 低频维度 i1=0
- 高频维度 i2=64



- 低频编码(例如 i1=0)在整个序列中变化缓慢,只有几次完整波动。比如从位置 m=0到 m=99,正弦值从0变化到接近=0.9。这种变化速度使得编码在远距离位置上仍然保持较高的相关性。例如,位置 m=0 和 m=50 的编码值分别为0和-0.262,尽管不完全相同,但它们的变化较慢,仍然保持一定的相关性。因此,低频编码能够捕捉到整个序列范围内的远距离依赖关系,例如一个句子的开始和结束之间的关系。
- 反之,高频编码从位置 m=0 到 m=99,正弦值从0变化到接近0.0099。这样的编码变化速度非常快,在短距离内编码值就会大幅度变化
至于实现:llama在attention之前就要计算旋转位置编码,然后才计算attention的值!
class LlamaAttention(nn.Module):"""Multi-headed attention from 'Attention Is All You Need' paper"""def forward(self,hidden_states: torch.Tensor,attention_mask: Optional[torch.Tensor] = None,position_ids: Optional[torch.LongTensor] = None,past_key_value: Optional[Cache] = None,output_attentions: bool = False,use_cache: bool = False,cache_position: Optional[torch.LongTensor] = None,) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[Tuple[torch.Tensor]]]:bsz, q_len, _ = hidden_states.size()if self.config.pretraining_tp > 1:key_value_slicing = (self.num_key_value_heads * self.head_dim) // self.config.pretraining_tpquery_slices = self.q_proj.weight.split((self.num_heads * self.head_dim) // self.config.pretraining_tp, dim=0)key_slices = self.k_proj.weight.split(key_value_slicing, dim=0)value_slices = self.v_proj.weight.split(key_value_slicing, dim=0)query_states = [F.linear(hidden_states, query_slices[i]) for i in range(self.config.pretraining_tp)]query_states = torch.cat(query_states, dim=-1)key_states = [F.linear(hidden_states, key_slices[i]) for i in range(self.config.pretraining_tp)]key_states = torch.cat(key_states, dim=-1)value_states = [F.linear(hidden_states, value_slices[i]) for i in range(self.config.pretraining_tp)]value_states = torch.cat(value_states, dim=-1)else:query_states = self.q_proj(hidden_states)key_states = self.k_proj(hidden_states)value_states = self.v_proj(hidden_states)query_states = query_states.view(bsz, q_len, self.num_heads, self.head_dim).transpose(1, 2)key_states = key_states.view(bsz, q_len, self.num_key_value_heads, self.head_dim).transpose(1, 2)value_states = value_states.view(bsz, q_len, self.num_key_value_heads, self.head_dim).transpose(1, 2)cos, sin = self.rotary_emb(value_states, position_ids)query_states, key_states = apply_rotary_pos_emb(query_states, key_states, cos, sin) #LlamaAttention的forward中在计算attention之前先计算旋转位置编码if past_key_value is not None:# sin and cos are specific to RoPE models; cache_position needed for the static cachecache_kwargs = {"sin": sin, "cos": cos, "cache_position": cache_position}key_states, value_states = past_key_value.update(key_states, value_states, self.layer_idx, cache_kwargs)key_states = repeat_kv(key_states, self.num_key_value_groups)value_states = repeat_kv(value_states, self.num_key_value_groups)attn_weights = torch.matmul(query_states, key_states.transpose(2, 3)) / math.sqrt(self.head_dim)if attention_mask is not None: # no matter the length, we just slice itcausal_mask = attention_mask[:, :, :, : key_states.shape[-2]]attn_weights = attn_weights + causal_mask# upcast attention to fp32attn_weights = nn.functional.softmax(attn_weights, dim=-1, dtype=torch.float32).to(query_states.dtype)attn_weights = nn.functional.dropout(attn_weights, p=self.attention_dropout, training=self.training)attn_output = torch.matmul(attn_weights, value_states)if attn_output.size() != (bsz, self.num_heads, q_len, self.head_dim):raise ValueError(f"`attn_output` should be of size {(bsz, self.num_heads, q_len, self.head_dim)}, but is"f" {attn_output.size()}")attn_output = attn_output.transpose(1, 2).contiguous()attn_output = attn_output.reshape(bsz, q_len, -1)if self.config.pretraining_tp > 1:attn_output = attn_output.split(self.hidden_size // self.config.pretraining_tp, dim=2)o_proj_slices = self.o_proj.weight.split(self.hidden_size // self.config.pretraining_tp, dim=1)attn_output = sum([F.linear(attn_output[i], o_proj_slices[i]) for i in range(self.config.pretraining_tp)])else:attn_output = self.o_proj(attn_output)if not output_attentions:attn_weights = Nonereturn attn_output, attn_weights, past_key_value